一文看懂深度学习模型中的“激活函数”
想了解什么是激活函数及其重要性吗?
前言
本文属于参考总结内容,参考链接请看文章末尾。参考作者:Harsh Maheshwari,Rukshan Pramoditha 致敬!
激活函数是一个深度神经网络中十分重要的组成部分,也是常常容易被忽略的部分。现在的深度学习框架十分便捷,所以对于底层的理解需求在减弱。此文便于各位读者更好的理解深度神经网络的组成。
激活函数:深度学习模型的关键组成部分
我们知道,深度学习模型由许多不同的组件组成,例如激活函数、批归一化(Batch Normalization)、动量(Momentum)、梯度下降(Gradient Descent)等。在本文中,我们将聚焦深度学习中的一个重要部分——激活函数,并通过回答以下问题对其进行详细讲解:
- 什么是激活函数?
- 为什么神经网络需要激活函数?如果没有激活函数会发生什么?
- 激活函数应具备哪些特性?
- 激活函数有哪些种类及其用途?
在本文中,我假定您已经具备基本的神经网络知识。那么,事不宜迟,让我们深入探讨激活函数。
什么是激活函数?
激活函数是用于转换神经网络中前一个节点输出信号的函数。这种转换使得网络能够学习数据中的复杂模式。简单来说,这就是激活函数的核心作用!虽然初听起来可能不太令人相信,但事实确实如此。
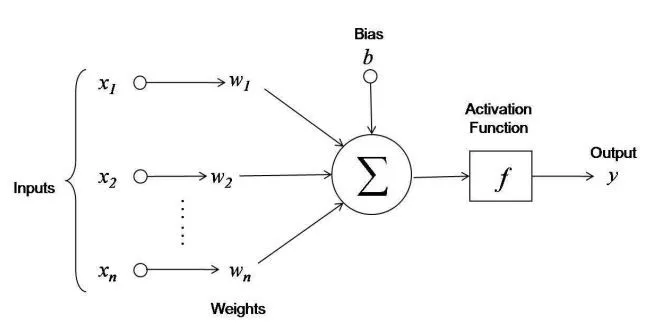
为什么需要激活函数?
您可能已经知道激活函数的基本作用:使神经网络能够学习数据中的复杂模式。那么,它是如何实现这一点的呢?激活函数通常是非线性函数,它们为神经网络添加非线性特性,从而使其可以学习更复杂的模式。还不太明白?让我们通过一个神经网络的例子来理解。
示例:神经网络
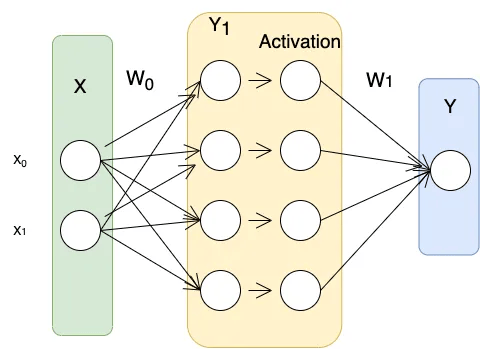
假设我们使用一个没有偏置(Bias)的简单神经网络,并将其输出表示为:
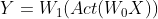
其中,Act 表示激活函数的输出(非线性转换)。
如果我们不使用任何激活函数,那么输出Y会变成:
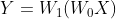
仔细观察上式,我们可以发现:
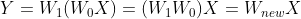
这表明,即使我们为网络添加了多个层,输入和输出之间的关系实际上可以用一个单一的权重矩阵来表示(即多个权重矩阵的乘积)。因此,没有激活函数的网络无论层数多少,都等价于一个简单的线性变换,隐藏层将变得毫无意义,因为它们无法引入任何非线性。而通过添加激活函数,我们引入了非线性变换,从而避免了这种简化。
示例:
没有激活函数的计算过程
- 隐藏层 1输入为 X计算公式为:X * W1 + b1
- 隐藏层 2输入为 X * W1 + b1计算公式为:(X * W1 + b1) * W2 + b2
- 输出层输入为 (X * W1 + b1) * W2 + b2 计算公式为:((X * W1 + b1) * W2 + b2) * W3 + b3
最终输出为:
((X * W1 + b1) * W2 + b2) * W3 + b3
我们可以进一步简化该表达式:(X∗W1∗W2+b1∗W2+b2)∗W3+b3
再展开得:(X∗W1∗W2∗W3)+(b1∗W2∗W3+b2∗W3+b3)
最终表示为:(X∗W)+B
其中:W=W1∗W2∗W3, B=b1∗W2∗W3+b2∗W3+b3
另一个重要作用是激活函数可以将神经元输出限制在所需的范围内。这很重要,因为激活函数的输入通常是 W*x + b(其中 W 是权重,x 是输入,b 是偏置),如果不加限制,这个值在深层网络中可能会达到很高的幅度,从而引发计算和溢出问题。
激活函数的理想特性
从上文可以看出,激活函数应具备以下特性:
- 非线性:激活函数必须是非线性的。
- 计算效率:由于激活函数会在每一层使用,因此计算效率尤为重要。
- 可微性:神经网络的所有组件都必须可微,激活函数也不例外。
- 避免梯度消失问题:设计激活函数时需要尽量避免梯度消失问题。尽管该问题的详细讨论超出了本文的范围,但可以简单理解为:激活函数的导数(相对于输入参数)不应严格受限于 -1 到 1 之间。
激活函数的不同类型
ReLU
ReLU 的全称是 Rectified Linear Unit,定义为:
f(x) = max(0, x)
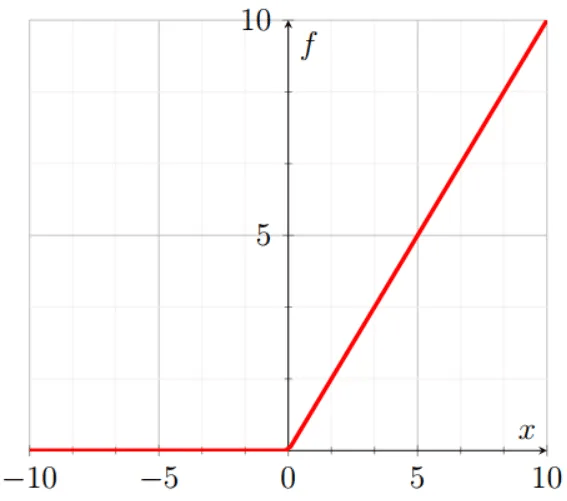
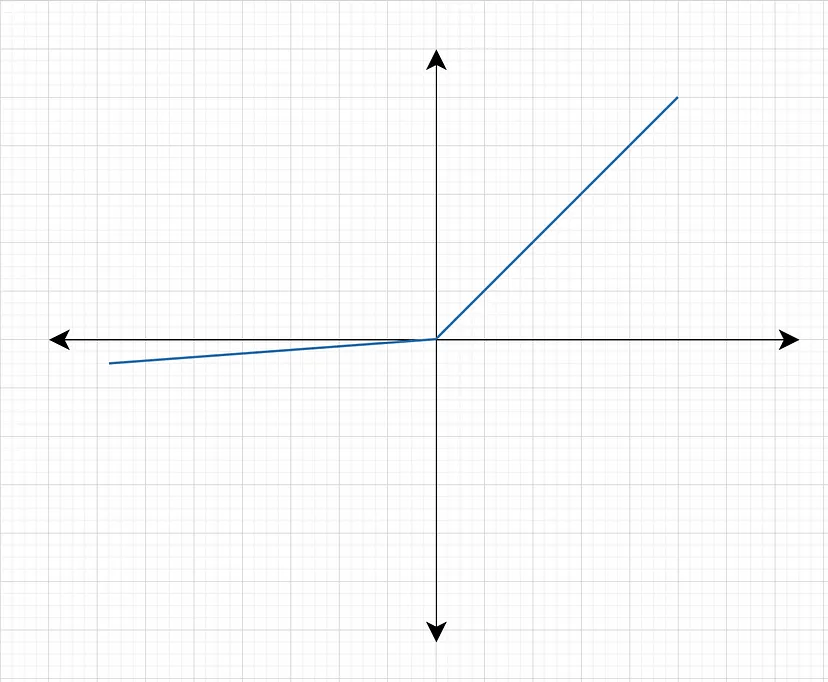
ReLU 是一种广泛应用的激活函数,特别是在卷积神经网络(CNN)中。它计算简单,不会饱和,也不会导致梯度消失问题。然而,ReLU 存在一个缺陷:对于负输入,其输出始终为零。这意味着某些节点可能完全失效,无法再进行学习。为了解决这一问题,可以使用 Leaky ReLU 或 Parametric ReLU,其定义为:
F(x) = max(αx, x),其中 α 是一个小的正数,用于确保负输入也有非零输出。
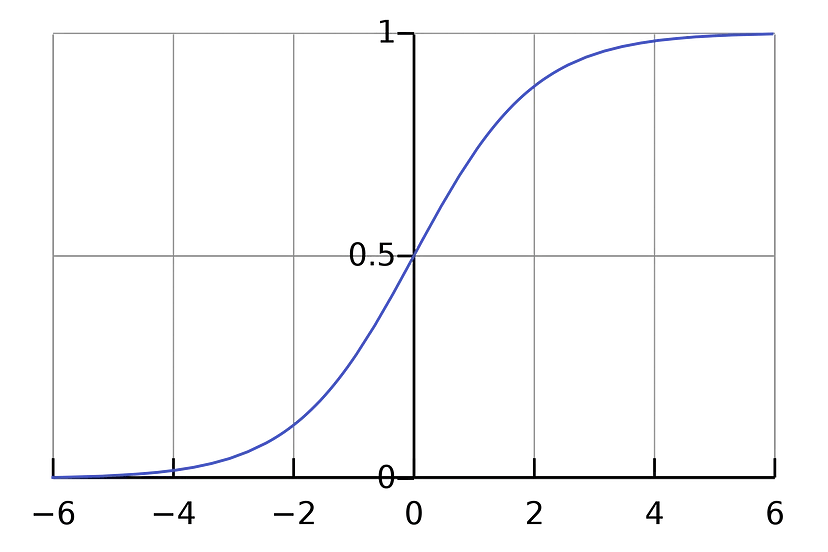
Sigmoid
Sigmoid 激活函数的计算开销较大,会引发梯度消失问题,并且其输出不是以零为中心的。通常,Sigmoid 主要用于二分类问题,并通常仅在神经网络的末层使用,用来将输出转换到 [0, 1] 的范围。一般情况下,Sigmoid 不会用作神经网络中的中间激活函数。
Softmax
Softmax 激活函数用于多分类问题。与 Sigmoid 类似,Softmax 的输出值也在 [0, 1] 范围内,所有种类的和为 1,因此它通常作为分类模型的最后一层使用,用于生成各类别的概率分布。
总结
通过以上讲解,相信您对神经网络为什么需要激活函数,以及激活函数的性质和类型有了更清晰的理解。如果您觉得这篇文章对您有帮助,欢迎在评论区留言!
参考链接
Everything you need to know about “activation functions” for deep learning models
What happens if you do not use any activation function in a neural network’s hidden layer(s)?