序列数据的高级交叉验证方法:避免数据泄露指南
在提高泛化性的同时保持数据的序列。
本文原作者:Kuriko Iwai,喜欢原作者的文章可以访问博客,点击这里
引言
交叉验证(Cross-validation)是一种有效的技术,可以防止过拟合,并为模型在未见数据上的表现提供更可靠的估计。
当应用于**序列数据(sequential data)时,交叉验证存在诸如数据泄漏(data leakage)和自相关(autocorrelation)**等风险,这些问题可能导致过于乐观的性能评估结果。
在本文中,我将探讨时间序列数据的交叉验证方法,包括专门为时间序列设计的交叉验证技术,并结合 PyTorch GRU 与 Scikit-Learn SVR 的实践实现进行说明。
什么是交叉验证(CV)
交叉验证(Cross-validation, CV)是一种用于评估机器学习模型泛化能力的统计技术。
CV 首先将原始数据集划分为训练集和验证集(或测试集)。
然后,它在不同的训练子集上反复训练模型,并在独立的验证集上评估性能,从而比单次训练-测试划分(train-test split)更可靠。
何时使用交叉验证
通过重复训练-验证过程,CV 可以在减轻模型偏差的同时防止过拟合。
应用 CV 的最佳实践包括:
- 模型选择或参数调优:通过小规模交叉验证提高选择/调参结果的可信度
- 序列数据分析:当单次随机划分可能导致数据泄漏时
- 高度类别不平衡的分类问题:随机单次划分可能造成类别极度不平衡,从而产生模型偏差。除了多种数据增强技术外,交叉验证也能缓解模型性能评估中的偏差
另一方面,在以下情况中,CV 并非必要:
- 拥有大型、非序列训练数据集,模型偏差风险较低
- 模型已经表现出稳定的损失曲线,具备良好的泛化能力
- 需要节省计算成本,例如进行快速初步实验
主要交叉验证方法
存在多种 CV 方法,每种方法都有其独特的数据划分方式。
下图比较了常见的 K-fold、Stratified K-fold 和 LOOCV 方法:
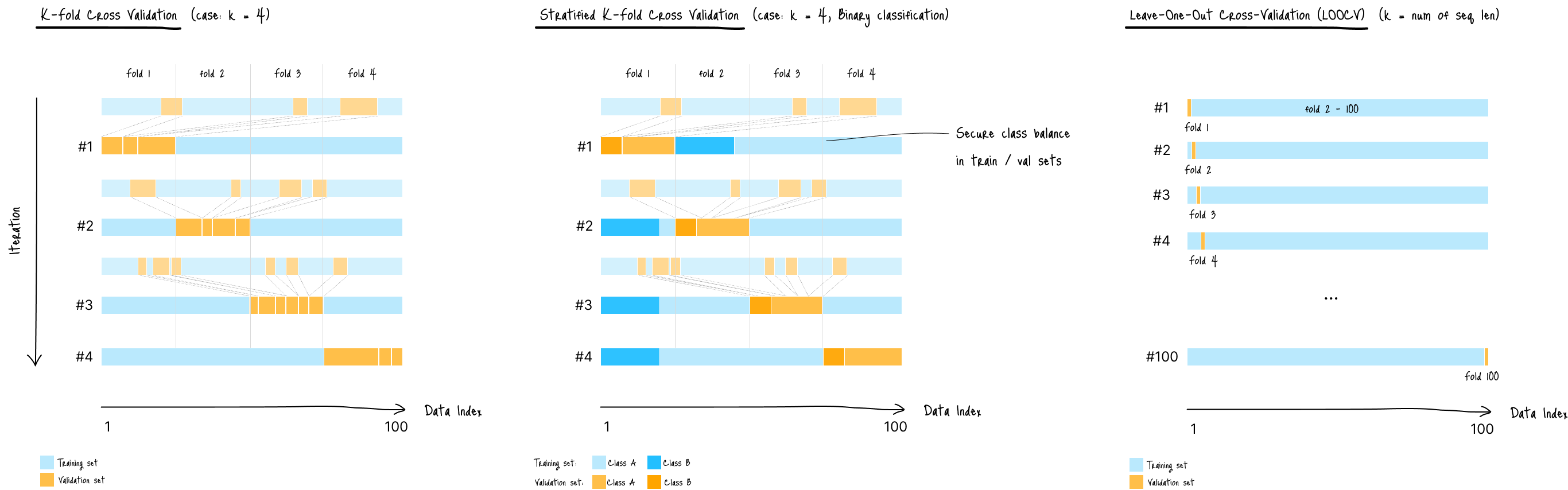
图 A:基于 K-fold 的交叉验证数据划分比较
图中说明:
- K-Fold CV(左):基于 K 个等大小折(fold)的平均结果评估模型性能
- Stratified K-Fold CV(中):K-fold 的变体,用于分类问题,保证每个折中的类别比例一致
- Leave-One-Out CV(LOOCV)(右):另一种 K-fold 变体,其中 K 等于样本总数,使每个样本恰好作为一次验证集
这些 K-fold 的概念也可应用于序列数据,但其有效性取决于核心原则。
我们将在下一节进一步探讨。
序列数据交叉验证的核心原则
在对序列数据进行交叉验证时,最关键的考虑因素是避免数据泄漏。
数据泄漏(Data Leakage)
数据泄漏是机器学习中的一个问题,即模型在训练过程中使用了来自训练数据集之外的信息。
这种信息泄漏会使模型在训练或验证阶段“作弊”,但在真正的未见数据上却无法达到相同的表现。
数据泄漏主要分为两种类型:
1️⃣ 直接泄漏(Direct Leakage)
一种简单情况:将目标变量本身作为特征包含在训练数据中。
例如:
为了预测房屋售价,模型在训练数据中包含了真实的房屋售价作为特征。
2️⃣ 间接泄漏(Indirect Leakage)
包含一个与目标变量高度相关、但在预测时未知的特征。
例如:
预测房价的模型将“当前房产税率”作为特征。
问题在于:
未来的房产税率在预测销售价格时是未知的。
数据泄漏示例流程

(图 B:房价预测中的数据泄漏示意图)
流程如下:
- 模型使用包括“房产税”在内的特征进行训练
- 模型预测房价为 $450,000
- 实际成交价为 $500,000
- 政府根据成交价更新房屋评估价值
- 基于新的评估价值计算新的房产税
- 模型再次使用新的税率作为特征进行训练
- 模型错误地学习到“高税率意味着高房价”
这种相关性是错误的,因为税率是在成交后计算的。
因此,税率不应被纳入训练数据,模型应专注于预测税前销售价格。
在序列数据中防止数据泄漏
在序列数据中,数据泄漏通常发生在:
未来信息(验证数据)直接或间接与过去信息(训练数据)混合。
为避免泄漏,我们需要:
1️⃣ 保持时间顺序:确保事件的时间序列不被破坏
2️⃣ 使用时间序列专用验证方法
3️⃣ 防止自相关影响:避免训练集和验证集中时间接近的数据点相互相关
条件 1 是必须满足的;根据数据类型,还需满足条件 2 和 3。
保持时间顺序
在处理序列数据时,必须保留时间顺序。
即使使用非时间序列专用的简单 CV 方法,也必须对数据排序,避免打乱(shuffle)。
单次训练-测试划分(Holdout)
这是最简单的方法,将数据集分为:
- 前半部分 → 训练集
- 后半部分 → 验证集
模型在历史数据上训练一次,并在验证集上评估:
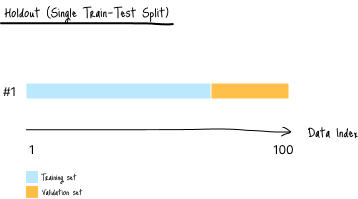
图 C-1:数据划分示意图
适用场景:
- 数据量较大
- 单次评估足以减轻偏差
缺点:
- 如果验证区间不能代表未来数据,模型表现可能失真
Monte Carlo 交叉验证
Monte Carlo CV 在每个折中随机抽样,前提是假设:
- 数据点彼此独立
- 数据统计特性(均值、众数、中位数等)随时间不变化
当这些条件满足时,随机采样不会破坏数据结构,是传统时间序列交叉验证的可行替代方法。
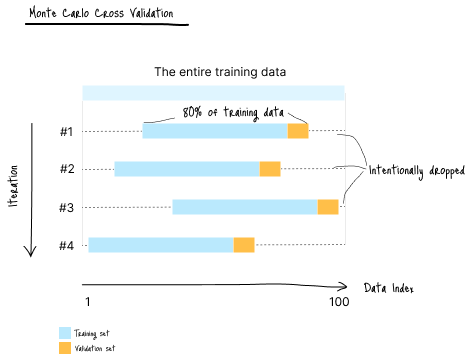
(图 C-2:数据划分示意图)
适用场景:
- 平稳数据且无自相关(例如多次抛硬币实验)
缺点:
- 若应用于非平稳时间序列,会完全破坏时间顺序
Blocked K-Fold 交叉验证
这是 K-fold 的一种改进版本,其中数据不进行打乱(shuffle)。
数据被划分为连续的区块(fold),每个区块依次作为验证集使用。
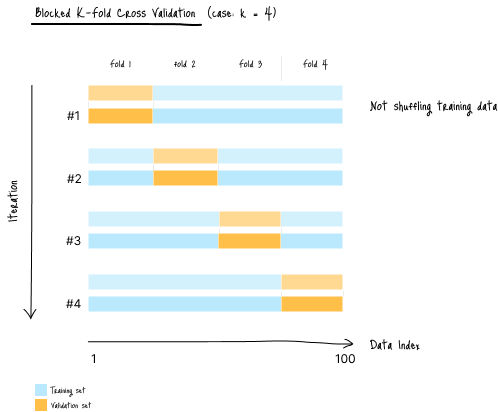
适用场景:
- 非平稳数据,但不存在自相关
- 样本量较小,需要充分利用所有样本进行训练与验证
缺点:
- 对于存在强自相关的数据,存在数据泄漏风险
时间序列专用验证方法
第二个核心原则是使用时间序列专用的验证方法。
这些方法专门设计用于保持时间顺序,重点在于模拟“向前预测”的场景,从而评估模型性能。
时间序列交叉验证(“Growing Window” 增长窗口)
这是一种顺序方法,其中每个折的训练集都会包含此前的全部历史数据。
模型在不断扩大的历史数据上重新训练,并在其后的固定大小数据块上进行验证。
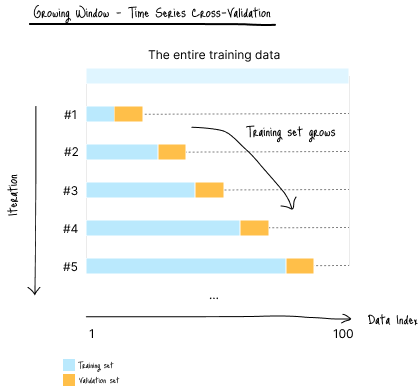
(图 D-1:数据划分示意图)
适用场景:
- 模型性能随着数据量增加而提升
- 需要模拟真实生产环境(模型定期用新数据更新)
缺点:
- 后期折次计算成本高,因为训练集越来越大
Walk-Forward 验证(“Rolling Window” 或 “Sliding Window”)
Walk-forward 方法与增长窗口方法理念相似,但训练窗口和验证窗口的大小保持不变。
随着验证窗口向前移动,旧的训练数据会被丢弃。
这是序列数据交叉验证中常见的方法。
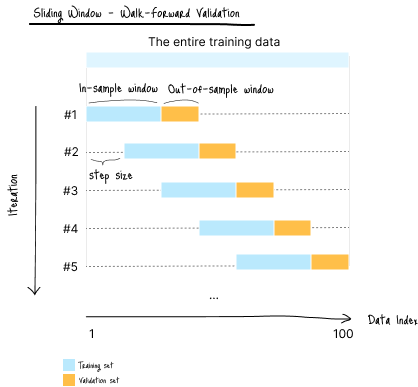
(图 D-2:数据划分示意图)
适用场景:
- 超长时间序列数据
- 较早的历史数据对未来预测相关性较弱
缺点:
- 计算成本高,因为每个滚动步骤都需重新训练模型
- 丢弃旧数据可能会丢失长期趋势或季节性模式
防止自相关
自相关是序列数据中典型的数据泄漏来源。
某些交叉验证方法通过在训练集与验证集之间**刻意加入时间间隔(gap)**来防止自相关。
带间隔的时间序列交叉验证(“Gap”)
该方法是在时间序列专用 CV 的基础上,在训练集与验证集之间加入一个时间间隔。
这个间隔可以增强训练与验证数据之间的独立性。
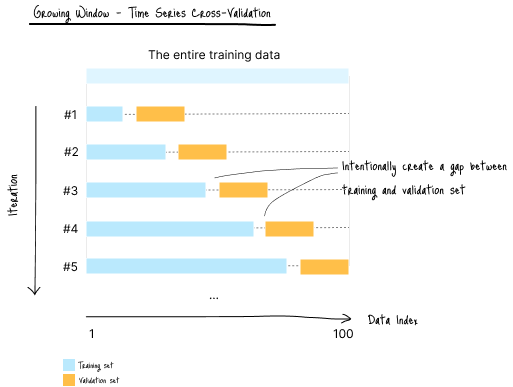
(图 E-1:数据划分示意图)
适用场景:
- 需要严格分离训练和验证数据,以避免数据泄漏
缺点:
- 间隔会导致部分数据无法用于训练
- 当数据量较小时,可能导致模型欠拟合
hv-Blocked K-Fold 交叉验证
hv-Blocked K-fold 是带时间间隔的 Blocked 验证的高级形式。
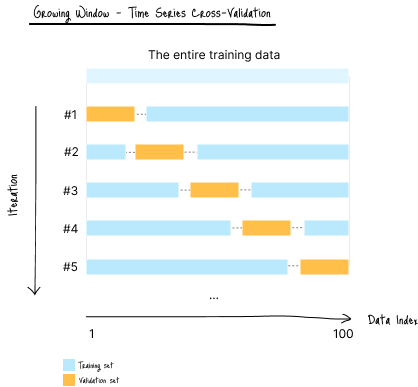
(图 E-2:数据划分示意图)
适用场景:
- 数据具有强自相关
- 需要更严格的阻断式验证以防止泄漏
缺点:
- 时间间隔导致部分训练数据被丢弃
- 数据量小时容易欠拟合
Purged & Embargo 交叉验证
Purged & Embargo 方法专门设计用于防止数据泄漏。
它会:
- Purged(清除):移除与验证期过于接近的训练数据
- Embargo(禁区):移除验证期之后可能受到未来信息影响的训练数据
适用场景:
- 时间序列具有高自相关
- 严格防止数据泄漏至关重要(例如金融领域)
缺点:
- 由于间隔和清除机制,会丢弃大量训练数据
- 相比普通 K-fold 方法,可能更容易欠拟合
以上就是关于序列数据交叉验证方法的全部内容。
方法的选择高度依赖于数据类型。
在下一节中,我将探讨模型的敏感性如何在交叉验证之后影响模型表现。
模拟实验(Simulation)
在本节中,我将探讨不同交叉验证方法在以下两种模型上的表现:
- 基于 PyTorch 构建的 GRU(门控循环单元)网络
- 基于 Scikit-Learn 的较简单模型 SVR(支持向量回归)
所有代码均可在我的 GitHub 仓库中找到:GRU / SVR
构建原始数据集
首先,我从 UC Irvine 机器学习仓库加载并处理了 CSV 数据:

(图 F:变量表截图)
在本项目中,我将使用时间序列数据(如 rain_1h, date_time 等)来预测 traffic_volume。
import pandas as pd
# 加载数据
file_path = 'data/Metro_Interstate_Traffic_Volume.csv'
df = pd.read_csv(file_path, sep=',')
# 添加与时间相关的特征(对 GRU 至关重要)
df['date_time'] = pd.to_datetime(df['date_time'])
df['year'] = df['date_time'].dt.year
df['month'] = df['date_time'].dt.month
df['hour'] = df['date_time'].dt.hour
df['day_of_week'] = df['date_time'].dt.dayofweek # 类别变量 (0 到 6)
df['is_weekend'] = df['day_of_week'].isin([5, 6])
df['is_holiday'] = df['holiday'].notna()
# 删除不必要列
df = df.drop(columns=['holiday', 'weather_description', 'date_time'], axis=1)
# 创建输入和目标变量
target_col = 'traffic_volume'
y = df[target_col]
X = df.drop(target_col, axis=1)
划分训练集与测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, shuffle=False
)
⚠ 为了保持时间顺序,在创建训练集和测试集时不能打乱数据。
X_test 用于评估泛化能力。在训练或验证阶段必须完全隔离,以避免数据泄漏。
特征转换
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from category_encoders import BinaryEncoder
首先区分数值特征和类别特征:
cat_cols, num_cols = [], []
for col in df.columns.to_list():
if col == target_col:
pass
else:
if df[col].dtype == 'object' or df[col].dtype == 'bool':
cat_cols.append(col)
else:
num_cols.append(col)
定义列转换器:
num_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
cat_transformer = Pipeline(steps=[
('encoder', BinaryEncoder(cols=cat_cols))
])
preprocessor = ColumnTransformer(
transformers=[
('num', num_transformer, num_cols),
('cat', cat_transformer, cat_cols)
],
remainder='passthrough'
)
转换数据:
X_train = preprocessor.fit_transform(X_train)
X_test = preprocessor.transform(X_test)
最终训练集包含:
- 38,563 个样本
- 16 个输入特征
定义 GRU 模型
接下来,在 PyTorch 中定义 GRU 类:
import torch.nn as nn
class GRU(nn.Module):
def __init__(self, input_size=X_train.shape[1], hidden_size=64, output_size=1):
super(GRU, self).__init__()
self.gru = nn.GRU(
input_size=input_size,
hidden_size=hidden_size,
batch_first=True
)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h_gru, _ = self.gru(x)
o_final = self.fc(h_gru[:, -1, :])
return o_final
这是一个简单的 many-to-one 架构:
- GRU 输出每个时间步的隐藏状态
- 最终时间步的输出用于生成单一预测结果
运行交叉验证
接下来定义 train_and_validate 函数。
该函数会根据指定的交叉验证方法,将 X_train 分成 5 个折,并在这些折上训练与验证模型。
按照交叉验证最佳实践:
- 每个 fold 都会重新初始化模型和优化器
实验统一参数
所有方法使用相同参数:
num_epochs= 300lr(学习率)= 0.001num_folds= 5test_size= 0.2
支持的交叉验证方法
在函数中,根据 validation_method 选择不同划分方式:
- Holdout
- Monte Carlo
- K-Fold
- Blocked K-Fold
- Growing Window
- Sliding Window
- Gap
- hv-Blocked K-Fold
训练与验证流程
每个 fold 内:
- 初始化 GRU 模型
- 初始化 Adam 优化器
- 使用 MSELoss
- 创建 DataLoader
- 运行训练循环
- 运行验证循环
- 记录 loss
训练阶段:
model.train()
for X_batch, y_batch in train_loader:
X_batch = X_batch.unsqueeze(1)
y_batch = y_batch.unsqueeze(1)
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
验证阶段:
model.eval()
with torch.inference_mode():
...
完成交叉验证后
完成所有 folds 后:
- 使用整个
X_train / y_train - 再次训练模型
最后返回:
{
'model': model,
"fold_train_losses": fold_train_losses,
"fold_val_losses": fold_val_losses,
"average_train_loss": np.mean(fold_train_losses),
"average_val_loss": np.mean(fold_val_losses)
}
这一部分展示了:
- 不同时间序列交叉验证方法
- 在深度学习模型(GRU)上的实现
- 与传统机器学习(SVR)的对比框架
进行推理(Performing Inference)
训练完成后,模型会在新的、未见过的数据(X_test)上进行推理。
通过记录损失值来评估模型的泛化能力。
# 将 X_test(numpy)转换为 torch 张量
X_test_float = torch.from_numpy(X_test).float()
y_test_float = torch.from_numpy(y_test.values).float()
# 创建测试数据加载器
test_dataset = torch.utils.data.TensorDataset(X_test_float, y_test_float)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=32, shuffle=False)
# 执行推理
model.eval()
test_loss = 0
criterion = nn.MSELoss()
with torch.inference_mode():
for X_batch, y_batch in test_loader:
X_batch = X_batch.unsqueeze(1)
y_batch = y_batch.unsqueeze(1)
outputs = model(X_batch)
test_loss += criterion(outputs, y_batch).item()
# 计算平均损失(MSE)
ave_test_loss = test_loss / len(test_loader)
实验结果
GRU
在所有方法中,Blocked K-Fold 取得了最佳的泛化损失(MSE)。
下图展示了:
- 所有折的 CV 损失曲线
- 平均 CV 损失(蓝线)
- 在
X_test上的泛化损失(红色竖线)
彩色区域表示模型学习的泛化能力(面积越小越好)。
当**平均 CV 损失(蓝线)反超泛化损失(红线)**时,说明出现了过拟合。
 (图 G:不同交叉验证方法下的 GRU 损失曲线对比)
(图 G:不同交叉验证方法下的 GRU 损失曲线对比)
结果分析:
- Blocked K-Fold 泛化表现最佳
- 带 Gap 的 K-Fold 次之
- 两者在约第 150 个 epoch 后开始过拟合
- 若加入 Early Stopping(早停机制),结果可能进一步优化
Growing Window:
- 表现较为平衡
- 能较好避免过拟合
- 同时保持较低泛化误差
Holdout 和 Monte Carlo 方法:
- 过拟合最严重
- 在测试集上误差极高(粉色区域大)
- 对该数据集和 GRU 模型而言,这两种方法不适合
SVR
在所有方法中,Sliding Window(滚动窗口) 取得最佳表现。
图中展示:
- 五折 CV 损失
- 平均 CV 损失(蓝线)
- 泛化损失(红线)
与 GRU 类似:
蓝线与红线差距越大,说明过拟合越严重。
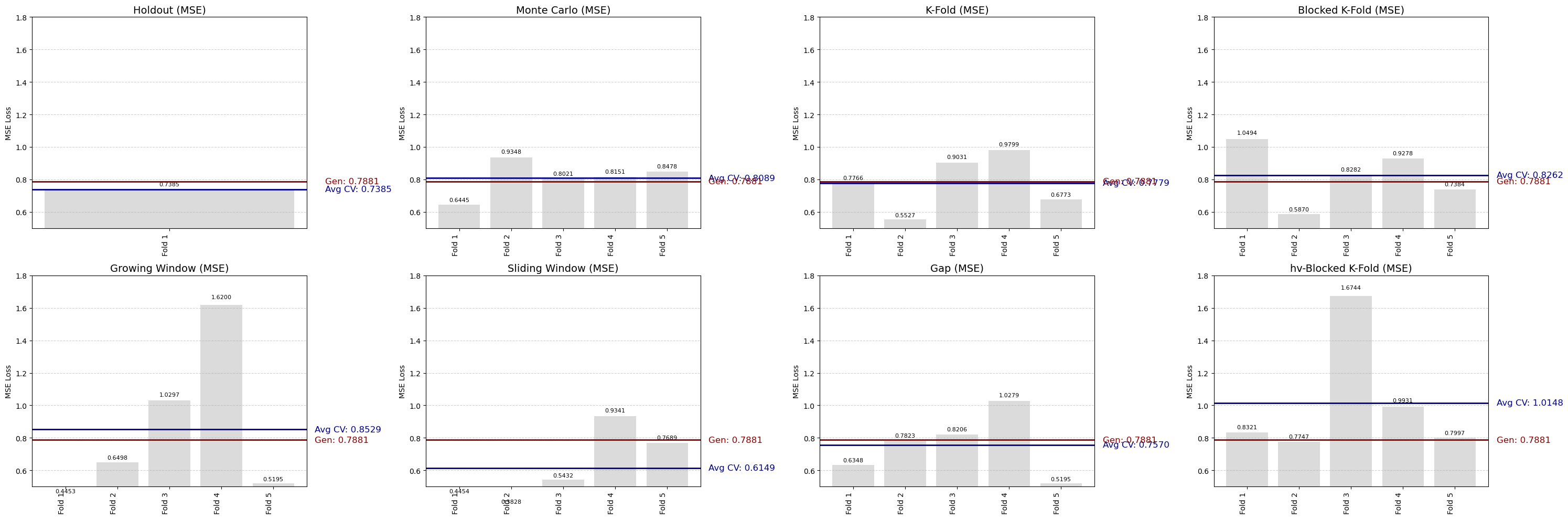
图 H:不同交叉验证方法下的 SVR 损失曲线对比
结果分析:
Sliding Window:
- 最低平均 MSE(0.6149)
- 稳定性高
- 说明对于 SVR,固定大小的训练窗口更适合处理本数据中的局部自相关问题
Growing Window 和 hv-Blocked K-Fold:
- 某些折出现最差误差
- 模型容易过度拟合历史数据
其他标准方法(Holdout、Monte Carlo、K-Fold):
- 泛化能力尚可
- 但整体损失较高
- 相比 Sliding Window,学习效果有限
总结(Wrapping Up)
交叉验证是评估时间序列模型的强大工具。
通过模拟原始数据结构,它可以:
- 提高模型泛化能力
- 有效避免过拟合
本次模拟实验表明:
- 为特定模型与数据类型选择合适的交叉验证方法至关重要
- 不同模型(GRU vs SVR)对 CV 方法的敏感性不同
最终目标是:
构建一个在真实生产环境中表现最佳的模型,而交叉验证正是通过模拟现实数据结构来实现这一目标的关键步骤。