机器学习与算法1.4 —— 从先验到后验,贝叶斯概率
为你什么打游戏上分那么难?所以先验概率是实际概率吗?
前言
又到了我们的逼逼赖赖环节,朋友们走到这里你很了不起了!谁都不爱枯燥的数学统计,当然也有能感受到其中迷人地方的人。从前面的条件概率,我们以及初步具备了不同条件下判断事物的能力。但这与机器学习有什么关系呢?
其实很简单,比如任何分类问题,都是基于不同条件的因素从样本到整体的推断。这其中的计算量很大,但对于我们现在的电脑来说不值一提。当理论走向现实的时候,多一点判断依据听起来不是件不错的事情嘛~
在这里继续科普统计学热知识,这将在后面的回归内容中涉及到:所有的统计学判断,预估,包括后续的回归方程所得到的结果!均是相关性!而并非因果!而并非因果!而并非因果!这很重要,因果代表你可以绝对相信,相关性通俗的来说只是可能性!所以我们对于数学,机器学习,所有所谓算法的态度应当是合理的工具!而非绝对的真理!
”保持谦卑,怀抱质疑,永远论证!“ —— 本人
多说一嘴,只有怀疑没有论证,那可就是杠精咯~
下面开始起飞!
贝叶斯学派是统计学的另一大分支,它的核心思想是通过观察新数据来更新我们对未知事件或参数的信念。贝叶斯学派基于贝叶斯定理,将新的信息与已有的信念(先验知识)结合,从而更新对事件或参数的概率判断。以下是贝叶斯学派的三个重要概念:贝叶斯公式、似然函数、先验概率和后验概率,我会逐一介绍它们的含义和应用。
1. 贝叶斯公式(Bayes’ Theorem)
贝叶斯公式是贝叶斯统计的核心,它描述了如何根据新的数据更新事件的概率。公式如下:
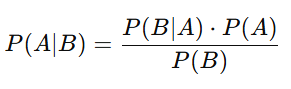
- P(A∣B):在 B 发生的条件下 A 发生的概率,称为后验概率。
- P(B∣A):在 A 发生的条件下 B 发生的概率,称为似然。
- P(A):事件 A 发生的先验概率,是我们在观察到 B 之前对 A 的信念。
- P(B):事件 B 的总概率,称为边缘概率,通常可以通过 P(B)=P(B∣A)P(A)+P(B∣A′)P(A′)计算。
贝叶斯公式表示,当有新证据(即事件 B)出现时,我们可以根据该证据更新对事件 A 的概率,即将先验概率 P(A) 更新为后验概率 P(A∣B)。
例子
咱们来个经典概率学癌症问题
假设一个人接受了癌症筛查测试,测试呈阳性。已知:
- 患有癌症的概率 P(癌症)=0.01
- 测试呈阳性的概率为 P(阳性∣癌症)=0.9
- 测试的假阳性率(即没有癌症但测试为阳性)为 P(阳性∣无癌症)=0.05
我们希望知道在测试结果为阳性后,该人确实患癌的概率 P(癌症∣阳性)。
应用贝叶斯公式:
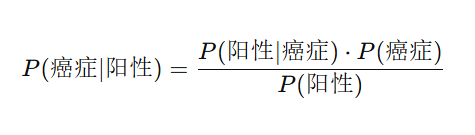
其中

通过代入,可以得出在测试为阳性后患癌的概率 = 0.0585。
2. 似然函数(Likelihood Function)
似然函数(Likelihood Function)在贝叶斯学派中用来表示观测到某组数据的可能性,即在假设参数取某一特定值的情况下,观测数据的可能性有多大。它帮助我们衡量模型在给定参数下生成数据的能力。
似然函数的定义
假设有一组数据 D={x1,x2,…,xn},且数据服从某种分布(例如正态分布)并由参数 θ (theta) 控制,则似然函数 L(θ) 定义为参数 θ 下观测数据出现的概率:L(θ∣D)=P(D∣θ)
例子
假设一个硬币的正面朝上的概率是 θ,抛硬币10次结果是6次正面朝上和4次反面朝上。对于某个具体的 θ 值,观测到6次正面、4次反面的概率为:L(θ∣D)=θ^6⋅(1−θ)^4
这里的似然函数就是对 θ 在已知数据下的支持程度的衡量。
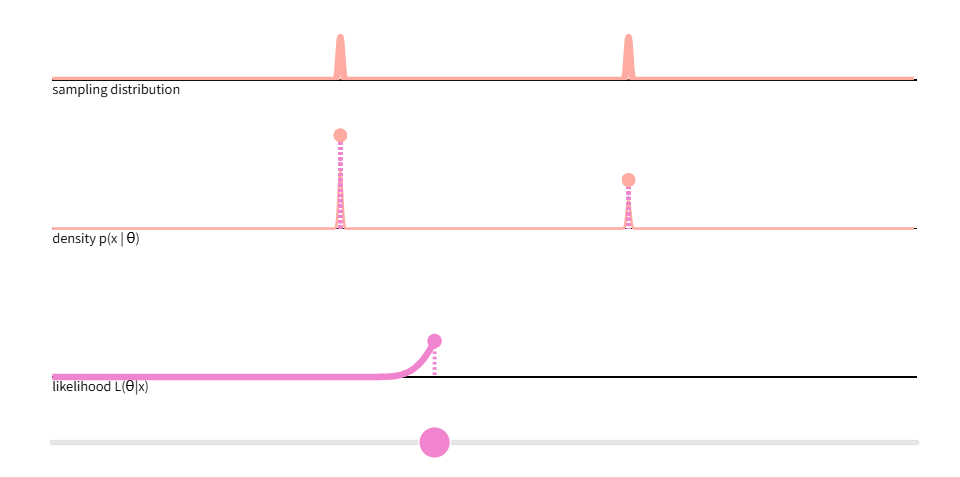
再来看下面的图片:
- 第一行代表只有两种结果的分布D(硬币正反面)
- 第二行代表密度分布,按照上面的例子,假设此时硬币向上的概率是0.6,那么抛十次硬币。
- 第三行是我们的可能性函数,我观测到6次正面、4次反面的概率 L(θ∣D) = θ^6⋅(1−θ)^4 = 0.0011943936
再来一个!
假设你是一位侦探,收到了一张纸条上写着一句话,可能来自一个特定的人。你怀疑有两个人分别写了这张纸条,比如小王和小李。为了判断是谁写的,你可以把小王和小李的写字风格当作参数,把纸条上的字迹当作数据。这里的似然函数就是你评估“在假设小王(或小李)写的情况下,纸条上这种字迹出现的可能性”。
我们用似然函数来“试探”不同的假设(参数值)是否适合数据。假如硬币正面朝上的真实概率是0.5,那么出现6次正面(从10次中)的可能性是多少?假如是0.6呢?0.7呢?我们会发现某些参数值让观察到的6次正面“更合理”或“更可能”,从而通过似然函数找到最佳参数的范围。
换句话说,什么事情总做不对,那么怀疑一下是不是咱们直觉上的假设出了问题呢?
3. 先验概率与后验概率
在贝叶斯统计中,先验概率和后验概率是核心概念。它们分别表示在观察新数据之前和之后对参数的信念。
先验概率(Prior Probability)
先验概率(Prior Probability),通常记为 P(θ),表示在观察到任何数据之前,对参数 θ 的信念或主观判断。先验概率可以根据历史数据、专家知识或主观判断来确定。
先验概率的重要性在于,它反映了我们在观测到数据之前的知识或偏好。例如,在医学诊断中,如果某种疾病在总体人群中的发生率很低,则我们对该病的先验概率也相对较低。
后验概率(Posterior Probability)
后验概率(Posterior Probability)表示在观察到数据之后对参数 θ 的信念,即结合先验概率和观测数据更新后的概率。它可以通过贝叶斯公式来计算:
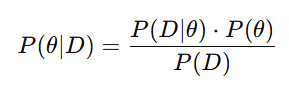
后验概率结合了观测数据的“似然”(即数据给定参数的概率)和先验概率,从而反映了新的数据对原有信念的影响。(嘿嘿上面的用法不就来咯)
例子
回到前面的癌症筛查例子中,先验概率 P(癌症)=0.01 表示我们在观察到测试结果之前对患癌的信念。而在观察到测试阳性结果后,我们通过贝叶斯公式计算出新的后验概率 P(癌症∣阳性),它表示在新的信息(阳性测试)下对患癌的信念。
让我们来继续细节
步骤1:定义先验概率
先验概率(Prior Probability)是我们在没有任何额外信息(即测试结果)之前,对患癌概率的原始估计。这里先验概率是基于人群的统计数据,即总体患癌的概率 P(癌症)=0.01。它反映了病人在进行任何测试之前,我们对他患癌可能性的初始信念。
先验概率代表了我们对病人健康状况的“初步认识”,在没有额外信息的前提下,认为他患癌的概率仅为 1%。
步骤2:观测数据
接下来,我们进行癌症测试,得到了一个阳性结果,这就是新的数据 BBB(即事件“阳性”)。现在我们希望利用贝叶斯公式,通过这个新信息来更新对病人患癌的判断。
步骤3:计算后验概率
现在,我们有了阳性结果,接下来我们使用贝叶斯公式计算后验概率 P(癌症∣阳性) :
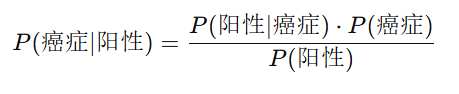
计算每个成分:
- 先验概率 P(癌症):我们已有,即0.01。
- 似然 P(阳性∣癌症):癌症患者测试为阳性的概率为0.9。
- 边缘概率 P(阳性):病人阳性结果的总体概率,由两部分组成:所以:P(阳性)=0.009+0.0495=0.0585
计算后验概率
代入贝叶斯公式:P(癌症∣阳性)=0.9⋅0.010.0585≈0.154
解释后验概率:在阳性结果出现后,后验概率 P(癌症∣阳性)≈0.154,即病人确实患癌的概率从初始的1%提高到了约15.4%。
先验和后验概率的对比
- 先验概率 P(癌症)=0.01:在没有测试信息前,我们仅基于人群平均情况,认为病人患癌的可能性为1%。
- 后验概率 P(癌症∣阳性)≈0.154:在阳性测试结果提供了新证据后,我们更新了这一概率,得到患癌的可能性约为15.4%。
结论:后验概率利用了新的测试结果信息,使我们可以更准确地推断病人确实患癌的可能性。贝叶斯方法的关键就在于利用新信息(测试结果)来更新对事件的认识(从1%提升到15.4%),这就是先验概率与后验概率的本质区别。
也就是说打游戏总是输,那你得想想这个匹配机制是不是你觉得的随机匹配咯
总结
- 贝叶斯公式:提供了一种更新概率的方法,将先验概率结合新证据得到后验概率。
- 似然函数:表示在假设参数值已知的情况下,观察数据的可能性,用于评估不同参数值对数据的解释能力。
- 先验概率和后验概率:先验概率是观察数据之前的信念,后验概率是结合新数据后的更新信念。
贝叶斯方法广泛应用于各种领域,如机器学习、医学诊断等,特别适用于需要结合主观知识与客观数据的场景。希望这对你理解贝叶斯统计的基本概念有所帮助!