TabNet:梯度提升模型的终结者?
一文带你了解TabNet,一种处理表格数据的深度神经网络
前言
本文属于搬运内容,原作者:Adam Shafi,原文链接在文章末尾。
TabNet 在表格数据上的表现兼顾了解释性和模型性能,但它能否取代提升树模型的地位?
TabNet 模型架构:TabNet 是如何工作的?
TabNet 模型架构。
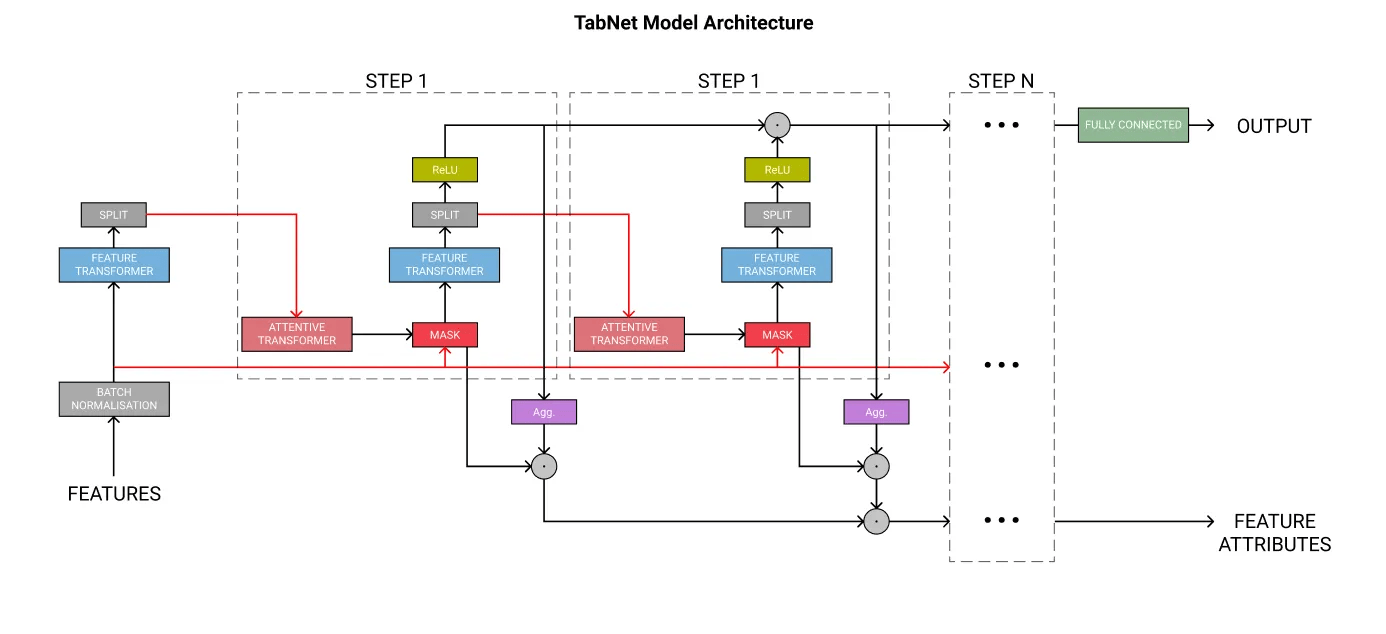
图片由作者制作,灵感来源于 论文链接。
简介
梯度提升模型(如 XGBoost、LightGBM 和 CatBoost)长期以来被认为是表格数据处理中的顶级方法。尽管在自然语言处理(NLP)和计算机视觉(CV)领域取得了快速进展,但在表格数据上,神经网络仍然经常被基于树方法的模型超越。
2019 年,谷歌推出了 TabNet。据论文所述,这种神经网络能够在多个基准测试中超越领先的基于树的模型。不仅如此,TabNet 内置了解释性,比提升树模型更具可解释性。同时,它无需任何特征预处理就可以直接使用。那么问题来了……为什么它没有被广泛采用?
TabNet 在解释性和先进性能之间找到了平衡。它易于实现,且需要的超参数调整有限。那么,为什么 XGBoost 仍然是 Kaggle 大师们的首选武器?
本文将深入探讨 TabNet 的理论,并展示一些模型实现的示例。
友情提醒
本文适合以下读者:
- 你了解什么是神经网络以及它的工作原理;
- 你熟悉如批归一化(Batch Normalization)、ReLU 和梯度下降(Gradient Descent)等术语;
- 你对神经网络中的注意力机制(Attention)有所了解。
什么是 TabNet?
概述
- TabNet 可直接输入原始表格数据,无需任何预处理,并通过基于梯度下降的优化进行训练。
- TabNet 使用序列化注意力机制(Sequential Attention),在每一步决策中选择最重要的特征,从而增强解释性,并将学习能力集中于最有用的特征上,提高学习效率。
- 特征选择是逐实例的,即特征选择可以针对训练数据集中每一行数据而不同。
- TabNet 使用单一深度学习架构同时完成特征选择和推理的任务,这种方法称为“软特征选择”(Soft Feature Selection)。
- 以上设计使 TabNet 具备两种解释能力:
关键点
尽管 TabNet 提供了解释性,它仍然是一个复杂的模型。以下为简要概述,但建议深入阅读 TabNet 原始论文以获取技术细节。
TabNet 的架构图展示了模型中的各个组件:
模型架构图
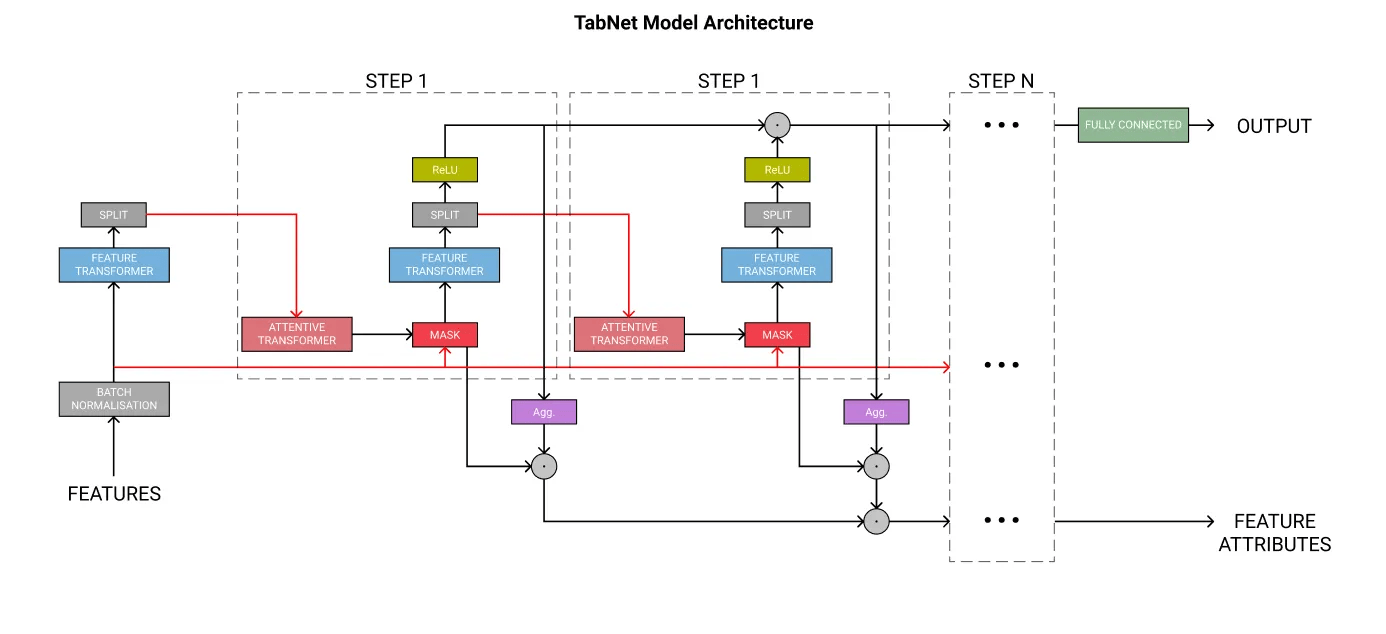
图片由作者制作,灵感来源于 TabNet 论文。红色线条用于避免箭头重叠造成混淆。
主要组成部分
1. 决策步骤(Steps)
- 每个决策步骤是一个由多个组件组成的模块,步骤数量是模型训练时的超参数。
- 增加步骤数量可以提升模型的学习能力,但同时也会增加训练时间、内存使用量,以及模型过拟合的可能性。
- 每个步骤在最终分类中都有投票权,且这些投票权被均等加权,类似于集成分类(Ensemble Classification)。
2. 特征转换器(Feature Transformer)
- 特征转换器本身也是一个具有独立架构的网络。
- 它包含多个层,其中一部分层在所有决策步骤中共享,而另一部分则是每个步骤独有的。
- 每一层包含以下组件:
- 如果对这些术语不熟悉,可以参考 Google 的机器学习术语表。
特征转换器架构
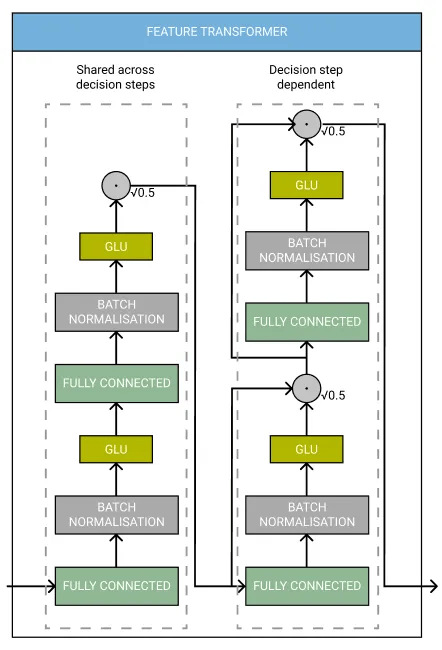
图片由作者制作,灵感来源于 TabNet 论文。
TabNet 论文的作者指出:特征转换器的输出使用 ReLU 激活函数。
特征选择
一旦特征被转换,它们将传递给 Attentive Transformer 和 Mask 以进行特征选择。
注意力转化(Attentive Transformer)
- Attentive Transformer 包含一个全连接层、批归一化(Batch Normalization)和 Sparsemax 归一化。
- 它还包括先前的尺度(prior scales),意味着它可以知道每个特征在先前步骤中被使用的程度。这些信息用于从上一个特征转换器的处理特征中推导出 Mask。
TabNet Attentive Transformer 模型架构
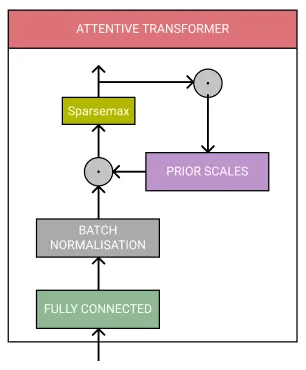
图片由作者制作,灵感来源于 TabNet 论文。
Mask的作用
- Mask 确保模型只关注最重要的特征,并且还用于推导模型的解释性。它基本上“遮蔽”了不重要的特征,这样模型只能使用那些 Attentive Transformer 认为重要的特征。
我们还可以通过观察某个特征在所有决策中被遮蔽的程度,来理解该特征的重要性,并进一步分析个别预测的结果。
软特征选择与可控稀疏性
TabNet 使用软特征选择,并在端到端学习中具备可控稀疏性。
- 这意味着 一个模型同时执行特征选择和输出映射,从而提高了性能。
- TabNet 采用 逐实例的特征选择,即每个输入都会选择不同的特征,每个预测可能使用不同的特征。
这种特征选择机制至关重要,因为它使得 决策边界 可以通过特征的线性组合来泛化,其中每个特征的系数决定了该特征的比例,最终这有助于模型的可解释性
代码
Dreamquark 还提供了一些非常好的笔记本,这些笔记本完美展示了如何实现 TabNet,同时也验证了原作者关于模型在某些基准测试中准确性的声明。
分类模型
Github:dreamquark-ai/tabnet
PyTorch 实现的 TabNet 论文:https://arxiv.org/pdf/1908.07442.pdf
回归模型
Github:dreamquark-ai/tabnet
PyTorch 实现的 TabNet 论文:https://arxiv.org/pdf/1908.07442.pdf
这两个示例都是可重复的,并且包括一个 XGBoost 模型,以便与 TabNet 的性能进行比较。
可解释性
TabNet 相较于提升树的一个关键优势是,它更具可解释性。我们不能像使用 SHAP 或 LIME 那样直接剖析梯度提升模型的预测。由于 TabNet 使用了 Mask,我们可以获得模型在全局(整个数据集)和局部(单个预测)层面上使用的特征的可解释性。
为了探索这一点,我将使用上面提到的分类示例,该示例使用了一个人口普查收入数据集。
特征重要性
我们可以查看单个特征的重要性,并且这些重要性之和恰好为 1。当我们从基于树的模型中获取这些数据时,它们可能会倾向于某个变量,或者倾向于具有大量唯一值的分类变量。在某些情况下,这可能会误导我们对模型行为的理解。
在这个例子中,当使用 TabNet 时,我们看到重要性分布更加均匀,这意味着它在特征的使用上更加平衡。虽然这不一定表示更好,也有可能存在 TabNet 过程中的缺陷。然而,原始论文的作者将特征重要性与合成数据示例进行了比较,发现 TabNet 确实使用了他们预期的特征。
来自 TabNet 和 XGBoost 的特征重要性
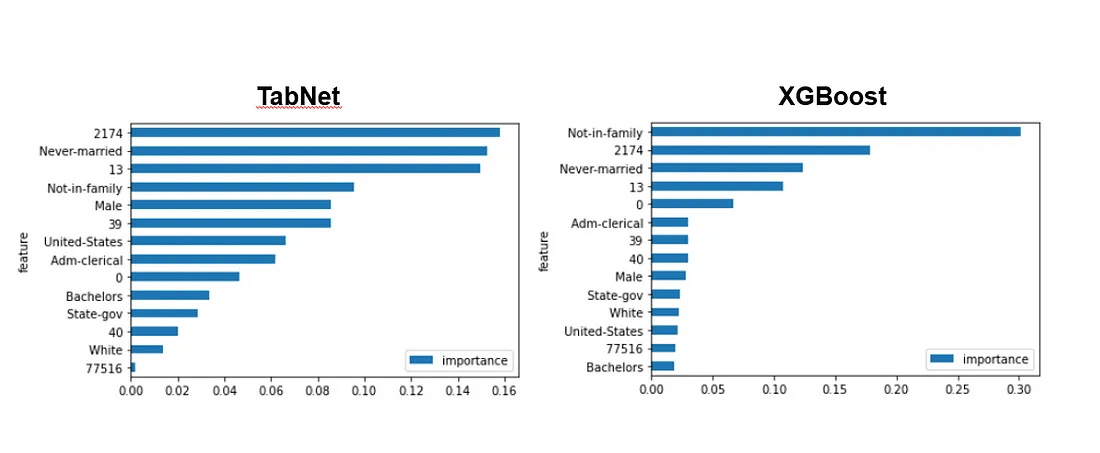
TabNet 和 XGBoost 模型在人口普查数据集上训练后的特征重要性。
图片由作者制作。
注意:带有数字作为特征名称的特征(例如 2174)似乎是匿名化的特征。
Masks
在TabNet中,mask指的是一个二进制的表示(本质上是由0和1组成的向量),它指示在给定步骤中哪些特征应该被使用。这些mask是由模型中的 Attentive Transformer(注意力变换器)部分生成的,负责为每个预测选择要关注的特征。
Mask的工作原理
- 特征选择:在模型推理过程中的每一步,都会应用一个mask。这个mask决定了哪些特征是活跃的(即用于预测),哪些特征是非活跃的(即被mask掉或忽略)。
- 按实例选择:特征的选择对于每个数据实例(数据行)是可以变化的。这意味着每一行数据在模型中选择的特征可能不同,从而使得模型能够更好地适应每个数据点。
- 稀疏注意力:mask确保在每次决策步骤中只关注少量特征,这样可以提高模型的计算效率,尤其是面对大量特征时。使用稀疏mask意味着每次只有少数特征在被激活使用。
通过使用 Mask,我们可以了解哪些特征在预测级别上被使用,我们可以查看所有 Mask 的聚合结果或单独的 Mask。
例如,对于第 0 行数据,即我们的测试数据的第一行,似乎 Mask 1 优先考虑数据集中的第 4 个特征,而其他 Mask 使用了不同的特征。
这可以帮助我们理解模型在做出预测时使用了哪些特征,它让我们对模型的预测有更多信心,因为我们能够分析预测背后的“原因”,并可能帮助我们理解模型如何处理未见过的数据。
然而,如何将其与实际的特征值关联起来尚不明确——我们不知道模型是因为特征值高还是低而使用该特征。更重要的是,我们无法直接理解交互项的作用。
人口普查 TabNet 模型中的 Mask 热力图
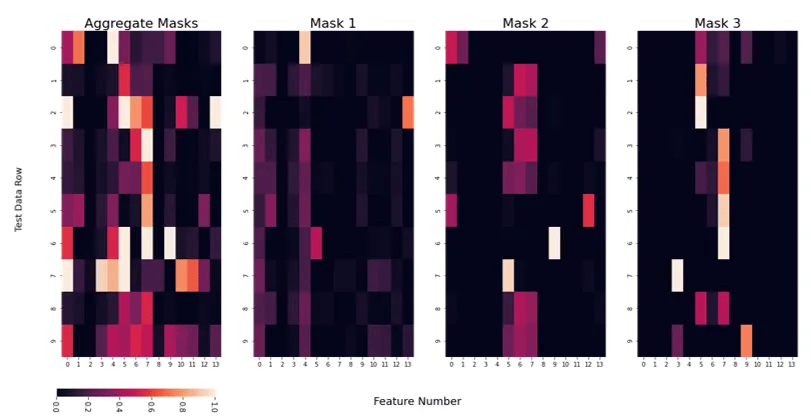
人口普查 TabNet 模型中的 Mask 热力图。较浅的颜色表示该特征被使用。
图片由作者制作。
使用自监督学习提高结果
TabNet 论文还提出了自监督学习,作为一种预训练模型权重并减少训练数据量的方式。
具体来说,这种方法会对数据集中的特征进行 Mask 处理,模型会尝试预测这些特征。然后使用解码器输出结果。
Dreamquark 的包中也可以进行类似的操作。
GitHub 链接:dreamquark-ai/tabnet
PyTorch 实现的 TabNet 论文:https://arxiv.org/pdf/1908.07442.pdf
使用自监督学习应该能够在更少的训练数据下获得更好的结果。
结论
TabNet是一种用于表格数据学习的深度学习模型。它通过顺序注意力机制选择一个有意义的特征子集,在每个决策步骤中进行处理。基于实例的特征选择使得模型的学习能力集中在最重要的特征上,而通过可视化模型的mask提供了可解释性。
希望你能看到,TabNet使我们能够在保持可解释性的同时,取得最先进的性能。随着AI监管的日益严格,了解我们的模型是如何工作的将变得愈加重要。我强烈推荐你在下一个项目或Kaggle比赛中尝试使用TabNet!