为什么“统计显著性”毫无意义
为数据驱动决策提供更好的框架,如何正确理解统计显著性
前言
本文属于搬运内容,原作者: Samuele Mazzanti,原文链接。
统计学显著在数据分析中对于方案的可行性与实效性具有良好的解释意义,但如果僵硬的依赖于基本的统计学解释,那也可能是种灾难。
尤其对于产品经理在做A/B test 时决定要不要执行一个方案时。
正文
数据科学家从事的其实是“决策”这门生意。我们的核心任务,是在不确定性中做出更明智的选择。
然而,当我们试图量化这种不确定性时,却常常依赖一个貌似权威的工具——统计显著性(statistical significance)。但它带来的理解往往是肤浅的,甚至误导性的。
本文将深入剖析为什么“统计显著性”本质上是有缺陷的:它依赖人为设定的阈值,营造了一种虚假的确定感,同时忽略了现实中的权衡因素。
更重要的是,我们将学习如何跳出“显著 vs. 不显著”的二元思维,构建一个以经济影响和风险管理为核心的更优决策框架。
一、从一个例子开始
想象你刚刚运行了一次 A/B 测试,目的是评估一个新功能是否能提升用户在网站上的停留时间和消费金额。
- 控制组:5000 名用户
- 处理组(实验组):另一个 5000 名用户
这两个数组(我们命名为 treatment 和 control)分别记录了两组用户的个人消费数据。
我们最自然的第一步,是比较两组的平均消费金额:
np.mean(control) # 输出:10.00
np.mean(treatment) # 输出:10.49控制组平均消费为 $10.00,处理组为 $10.49,增加了约 5% —— 听起来很不错,对吧?
但接下来,我们往往会问一个经典问题:
这个结果在统计上显著吗?
此时,大多数数据科学家会立刻拿出判断“统计显著性”的两大工具:
- p 值(p-value)
- 置信区间(confidence interval)
下面我们一个一个讲清楚。
二、p 值是什么?
p 值的核心问题是:
如果处理组和控制组之间实际上没有差异,我们观察到这么大的结果的概率有多大?
换句话说,我们暂时假设两个组之间并无实际差异,接着检验观察到的结果是否极端得超出了“随机波动”的合理范围——一种“反证法”的逻辑。
具体来说,如果两组真的没有差异,那它们就是从同一个总体中随机抽取的两个样本。因此我们可以将两组合并成一个数组 combined:
combined = np.concatenate([treatment, control])
然后我们可以对这个数组进行随机打乱,再重新划分出新的“实验组”和“对照组”。
这就相当于免费重新进行了一次实验。而不同的是:这一次我们知道两组确实没有差异,因此任何结果都是纯随机产生的。
这种方法被称为置换检验(permutation test)。
我们可以无限次运行这个“虚拟实验”。比如我们运行 10,000 次:
permutation_results = []
for _ in range(10_000):
combined = np.random.permutation(combined)
perm_treatment = combined[:len(treatment)]
perm_control = combined[-len(control):]
permutation_results.append(np.mean(perm_treatment) - np.mean(perm_control))
这相当于运行了 10,000 次“虚拟实验”,并记录下每次实验的组间均值差异。注意:我们知道这些差异都是随机产生的。
然后我们绘制这些结果的直方图:
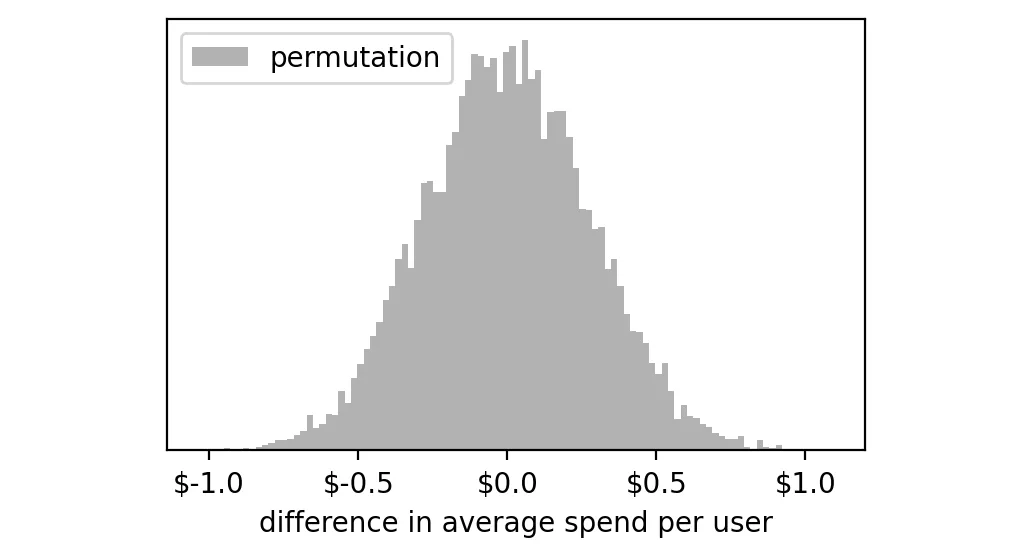
这 10,000 个差值的分布大致围绕 0 对称分布,说明在“没有真实差异”的假设下,两组的平均差值基本为 0,仅因为随机性,才偶尔会出现偏离(如 -1 美元到 +1 美元的极端值)。
那么,问题来了:
观察到像 $0.49 这样极端的结果,有多大概率?
我们只需计算,在这 10,000 次实验中,有多少次差值 ≥ 0.49:
np.mean(np.array(permutation_results) >= 0.49) # 结果:0.04也就是说,有 4% 的虚拟实验结果大于 +$0.49。
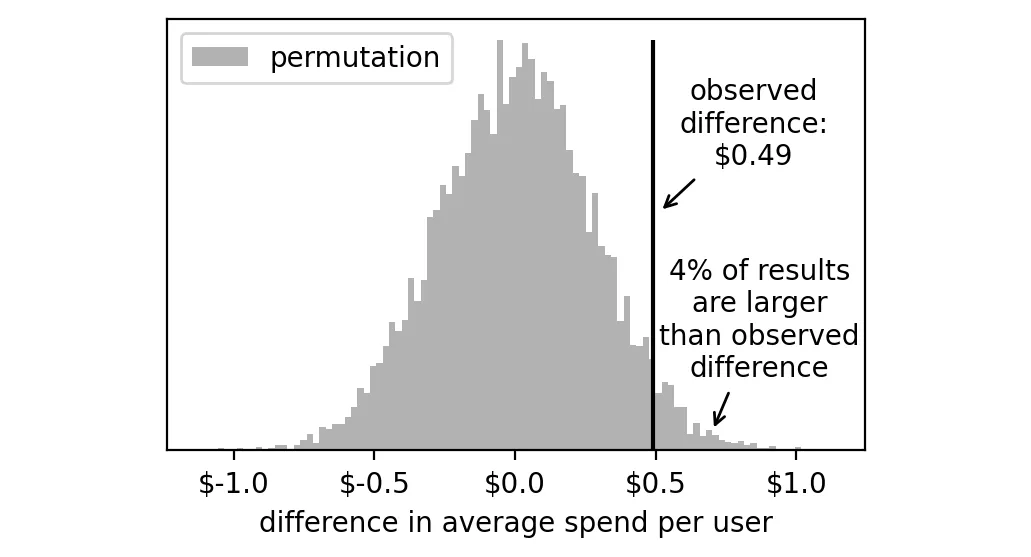
由于我们并不知道真实实验的差异是在左尾还是右尾(可以是正偏也可以是负偏),所以我们要将这个结果乘以 2,得到最终的 p 值:
p-value = 4% × 2 = 8%这就是我们所关心的 p 值了。
那么,8% 高还是低?
根据传统统计学“约定俗成”的做法,通常以 5% 作为判断是否“显著”的门槛:
- 如果 p < 5%,我们说结果是“统计显著”的;
- 如果 p ≥ 5%,我们认为差异可能只是随机导致的,不显著。
而在我们的例子中,p 值为 8%,因此根据这个规则:
我们将得出结论:$0.49 的差异不具有统计显著性。
接下来,我们再看看另一个常用的工具:置信区间 是怎么运作的。
三、置信区间(Confidence Interval)
我们在计算 p 值时的前提是假设处理组和对照组之间没有差异。而计算置信区间时,采用的是完全相反的假设:
假设当前观察到的处理组和对照组的分布,真实地代表了背后的总体分布。
所以,我们同样可以通过大量“虚拟实验”来模拟结果 —— 不同的是:
这一次,我们会分别从原始的处理组和对照组中抽样,而不是像之前那样把它们合并再打乱。
为什么不能再洗牌?
因为现在我们假设两组本来就不一样。若我们将数据打乱再分组,得到的新样本组均值将不再有变化,因此失去了意义。
所以我们需要更聪明的办法:有放回地抽样(sampling with replacement),从每个原始组中各自进行抽样。
这就模拟了从原始总体中再次独立抽样的过程,而且每次都能获得略有不同的数据。
这种算法就叫做 自助法(Bootstrapping)。
我们运行 10,000 次自助法实验:
bootstrap_results = []
for _ in range(10_000):
bootstrap_control = np.random.choice(control, size=len(control), replace=True)
bootstrap_treatment = np.random.choice(treatment, size=len(treatment), replace=True)
bootstrap_results.append(
np.mean(bootstrap_treatment) - np.mean(bootstrap_control)
)
现在,我们得到了 10,000 次“虚拟实验”的结果,全部保存在 bootstrap_results 列表中。
我们可以将这些结果绘制成直方图。为了更有对比性,我们也可以将它与之前置换检验(permutation test)的直方图一起绘制:
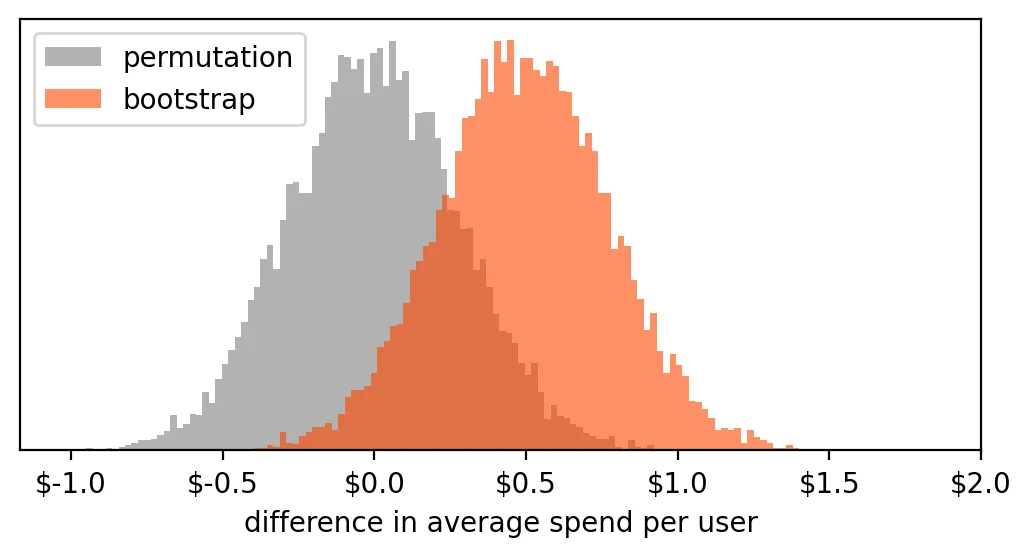
两种直方图代表了不同的含义:
- 置换检验(Permutation): 假设处理组和对照组来自同一个总体(即本质上没有差异),因此任何观察到的差异都仅由“随机性”导致。
- 自助法(Bootstrap): 假设当前观察到的分布是可靠的,我们通过对其重复采样,来估计这个平均差值的波动范围与不确定性。
如何计算置信区间?
我们只需在 bootstrap_results 的结果中找到左右两端各 2.5% 的点位,也就是第 2.5 和第 97.5 百分位数。
可以通过 numpy.percentile 快速计算:
lower_bound = np.percentile(bootstrap_results, 2.5) # 输出:-0.0564
upper_bound = np.percentile(bootstrap_results, 97.5) # 输出:1.0423
这表示我们的 95% 置信区间 是:
[-0.0564, 1.0423]
我们再来看一下这两个区间界限在直方图中的位置:
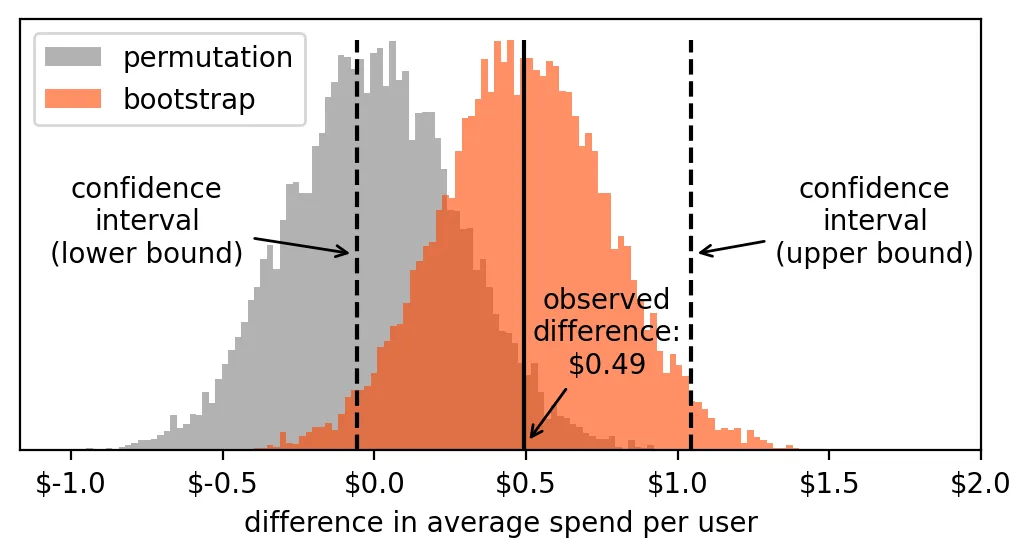
结论:
由于这个置信区间包含了 0,说明我们不能排除“无差异”的可能性。
换句话说:
我们不能有信心地说处理组的均值显著高于对照组。
这个结论与我们在前面计算的 p 值(8%)是一致的:都认为差异 不具统计显著性。
四、“统计显著性”到底哪里出了问题?
如果你在前面的分析中已经感受到“统计显著性”的整个判断流程似乎哪儿不太对劲——那你并不是孤单的,我完全赞同。
“统计显著性”这个概念存在诸多严重问题,主要包括:
- 它极其武断(Arbitrary)
- 它制造了一种虚假的确定感(False sense of certainty)
- 它完全没有考虑风险偏好(Risk aversion)
下面我们逐一解释:
武断得令人发指
判断显著性的常用门槛是 5% 或 1%,你有没有想过:为什么偏偏是这两个数字?
答案其实是:它们只是“好看”的整数而已。我们完全可以换成 7%,甚至 0.389% —— 从理论角度来看,任何阈值都一样。
也就是说,所谓“是否显著”的判断标准,本质上就是一个人造标准,没有科学依据。
制造了虚假的确定感
只要引入“阈值”,我们就会自动陷入一个二元对立的陷阱:
是 / 否?显著 / 不显著?可以发布 / 不可以发布?
这种“是就是,不是就不是”的逻辑,容易让人误以为统计结果是确定的。
但现实是:科学中从不存在绝对的确定性。任何实验结果都存在不确定性,差异也处于连续光谱上,而非“开/关”的开关。
忽略了“风险厌恶”的心理与实际需求
风险厌恶(Risk Aversion)是实际决策中极其重要的一个因素。
人类,尤其是企业,在做决策时往往宁可放弃潜在收益,也要避免风险和损失。
而 p 值与置信区间这种方法,完全不考虑风险偏好,只是站在统计角度告诉你结果“够不够显著”,没有告诉你实际的代价与机会。
那我们该怎么办?
是否意味着“统计显著性”不可依赖,我们就不能做决策了?
当然不是。我们真正要做的,是改变我们使用统计工具的方式,比如像前面用 bootstrapping 得到的分布直方图。
五、更好的数据决策方法:从经济影响与风险角度出发
每一个决策都伴随着风险与机会,数据驱动的决策也不例外。
我们回到前面的例子。假设我们的网站每月有 100 万用户,那么:
期望效益 = $0.49(每人提升)× 100万用户 × 12个月 = 约 $590 万/年
听起来不错,对吧?
但——这只是期望值,它没有反映出结果可能的波动。所以我们该怎么全面评估呢?
将每次虚拟实验转化为经济影响
我们可以将 bootstrapping 得到的每一个实验结果(单位是“每用户”提升金额),乘以 100 万用户、再乘以 12 个月,来模拟每种可能带来的年度经济影响:
bootstrap_impact = np.array(bootstrap_results) * 1_000_000 * 12
并将这些数据绘制成直方图:
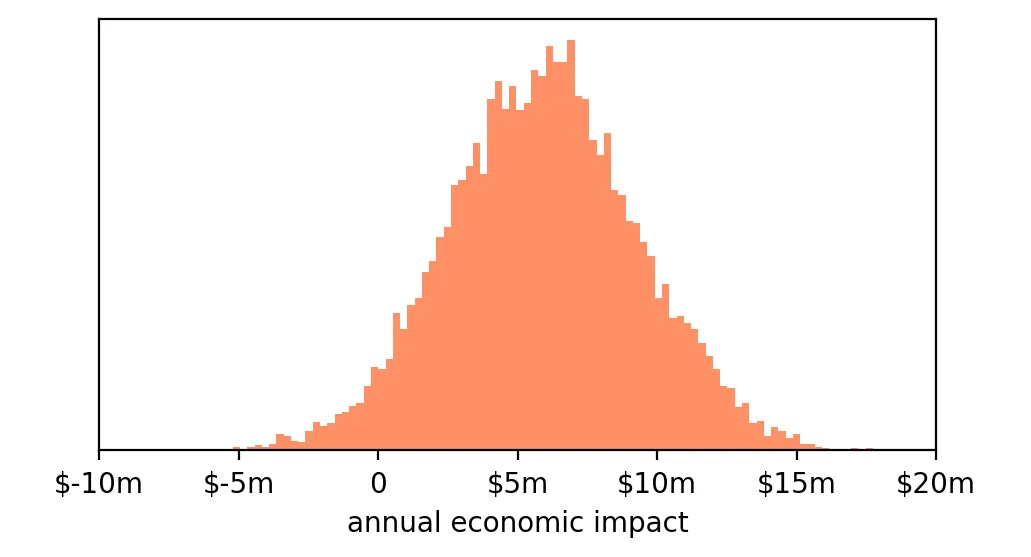
如你所见,大多数结果集中在 +$600 万左右,但波动范围可以从 –$400 万 到 +$1600 万 不等。
如何量化风险与机会?
我们重新回到更现实的问题:
- 风险(Risk):我们可能会赔钱。尽管最可能的结果是赚 $600 万,但也有小概率出现损失。
- 机会(Opportunity):大多数情况下我们会赚钱。
于是我们分别量化这两种情景:
🟥 亏损的概率:3.8%
➡️ 如果亏损,平均亏损为 $136 万
🟩 盈利的概率:96.2%
➡️ 如果盈利,平均收益为 $622 万
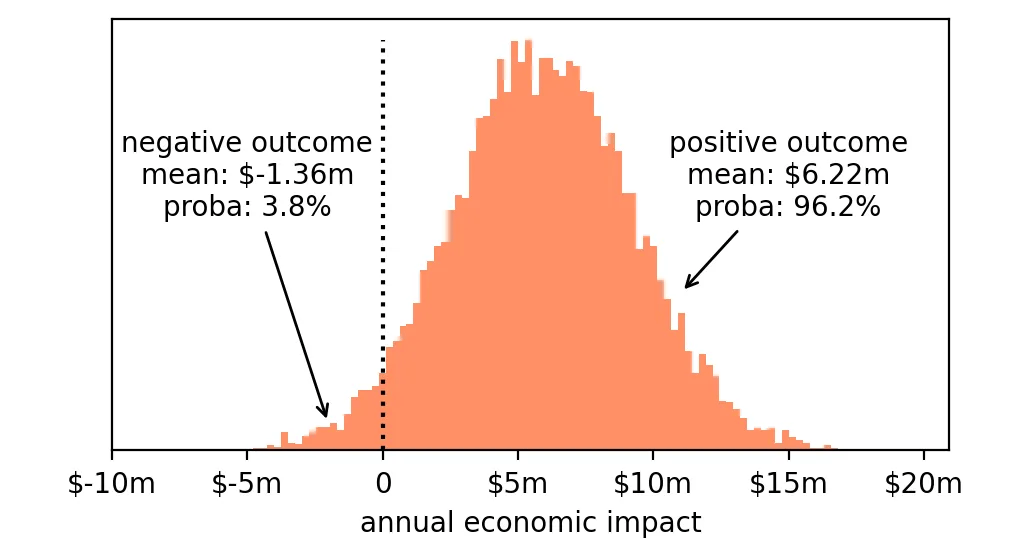
那我们该发布这个功能吗?
答案其实没有唯一标准,而是取决于很多实际因素,比如:
- 我们是否能接受 3.8% 的亏损风险?
- 是否愿意用更多用户来做更大规模的测试,从而降低不确定性?
- 公司是否有时间与预算来开展新的实验?
- 是否有其他更有潜力的功能值得优先测试?
这些问题没有唯一的答案。
真正的重点在于:
我们现在掌握了更全面、更真实的评估工具。 我们在做决策时,不再是“显著 / 不显著”的二选一,而是明明白白地看到:风险有多大,机会有多值。
我们可以做权衡,也应该做权衡,而不是把复杂现实简化成一个不负责任的句子:
“p 值没过 0.05,不能发。”