从原理出发理解 Flash Attention Part2(包含动画解释)
FlashAttention —— 全面可视化深入解析
前言
这是系列文章《从原理出发理解 FlashAttention》的第二部分。本文属于搬运内容,原作者:Sascha Kirch,原文链接。
Attention 机制无疑是现代深度学习架构中最重要的构件之一。
它被广泛应用于各类任务中的前沿模型中,
从自然语言处理(NLP)到计算机视觉(CV),无所不在。
但与此同时,Attention 机制也是这些模型中计算最昂贵的操作之一。
因此,研究界自然投入了大量努力,希望能让它变得更快、更省内存。
不过,大多数方法的优化思路是——对 Attention 机制进行近似计算(approximation),这常常会带来准确率的下降。
而在本系列的第二部分中,我们将深入剖析 FlashAttention 的细节,
看看它是如何做到:
- 速度提升高达 7.6 倍(7.6x speed-up),
- 并且在计算精确 Attention 得分的同时,
- 实现 O(N) 的内存复杂度!
1. 回顾第一部分的内容
在本系列的第一部分中,我们为理解 FlashAttention 论文打下了坚实的基础。我们建立了对 Attention 机制的基本直觉,了解了它的工作原理以及它在模型中的位置;我们还简要了解了现代 GPU 的架构、CUDA 编程模型以及 GPU 的内存层级结构。
随后我们深入探讨了在 GPU 上如何执行矩阵乘法,并介绍了几种关键的优化方法:
- 共享内存(Shared Memory):将常用数据存放在核心附近;
- 块切分(Block Tiling):每个线程计算多个结果,重用已加载的数据;
- 内核融合(Kernel Fusion):将多个计算步骤合并为一个内核,避免中间结果的重复读写。
最终我们看到了如下图示,它清楚地揭示了 Attention 的主要性能瓶颈:
我们需要对中间结果的 N×NN \times NN×N 矩阵进行大量的读写操作, 不仅耗时,而且内存消耗极大。
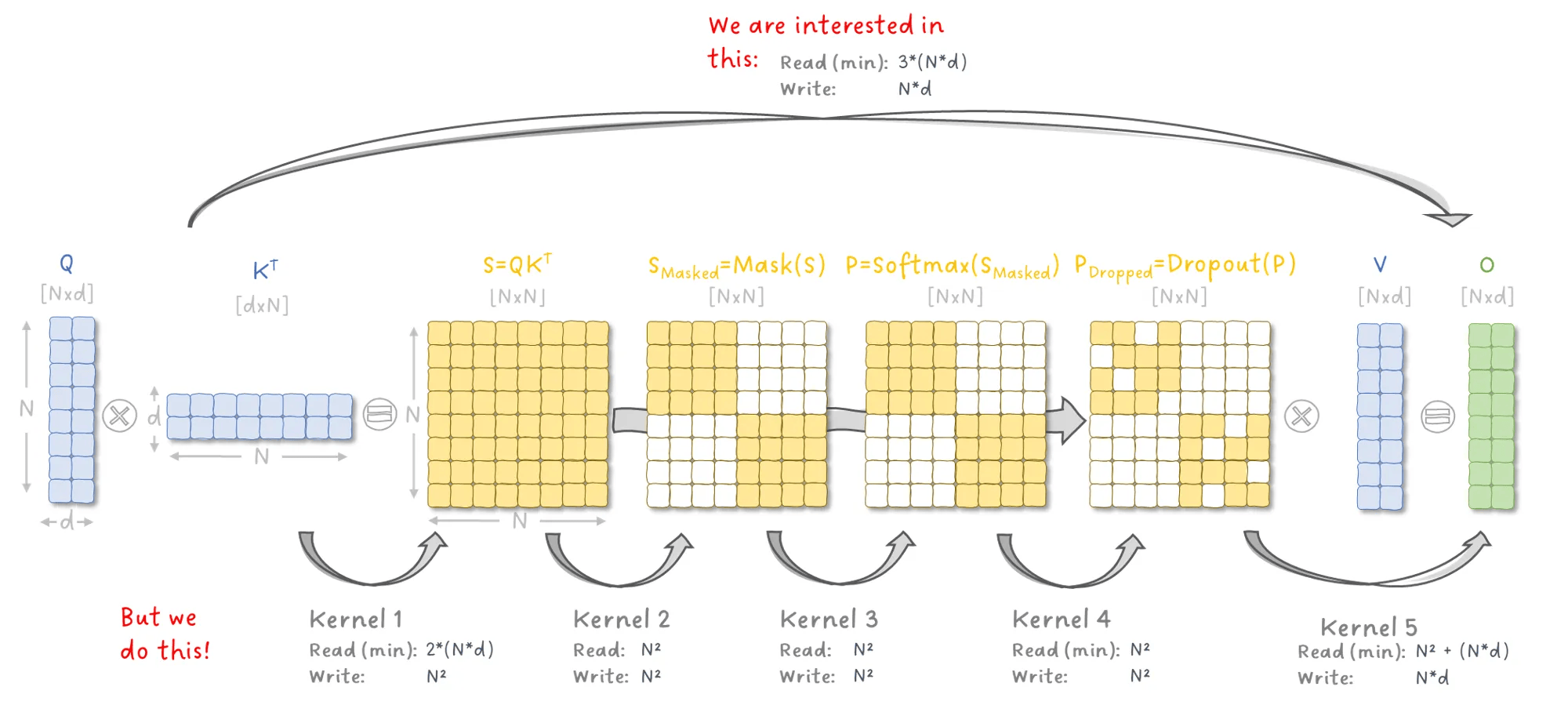
图 1:Attention 层每个内核的读写操作示意图。图像作者:Sascha Kirch
我们还发现了两个关键障碍,使我们无法像优化矩阵乘法那样优化 Attention:
- SoftMax 操作阻止了内核融合,因为它是对整行向量 x 操作的,而不是可以切块并行的;
- 我们还需要保留中间结果用于反向传播,以计算梯度。
理解这两个问题并不容易,如果你已经看到这里,那真的很棒,恭喜你!🎉
现在,让我们继续保持势头,开启接下来的旅程:
看看 FlashAttention 是如何解决这些问题的!
2. FlashAttention
论文标题 “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness” 本身就非常明确,已经概括了它解决的主要问题:
- Fast(快速):大幅缩短执行时间。 在 Attention 层中达到了 7.6 倍提速,在从零开始训练 GPT-2 时达到了 3.5 倍提速。
- Memory-Efficient(内存高效): 显著减少内存使用,支持训练更大的模型、更长的上下文、更大的 batch。 标准 Attention 的内存复杂度为 O(N2),而 FlashAttention 为 O(N)。
- Exact Attention(精确 Attention): 不同于 Linformer、Performer 或 Reformer 等方法通过近似 Attention 实现加速和省内存, FlashAttention 在计算精确 Attention 的前提下完成了加速与内存优化。
- IO-Awareness(I/O 感知): FlashAttention 充分利用现代 GPU 的内存层级结构, 通过使用 共享内存存放中间结果,只将最终结果写入全局内存,从而大大减少内存带宽压力。
这些优势可以通过下面这张图进行直观展示:
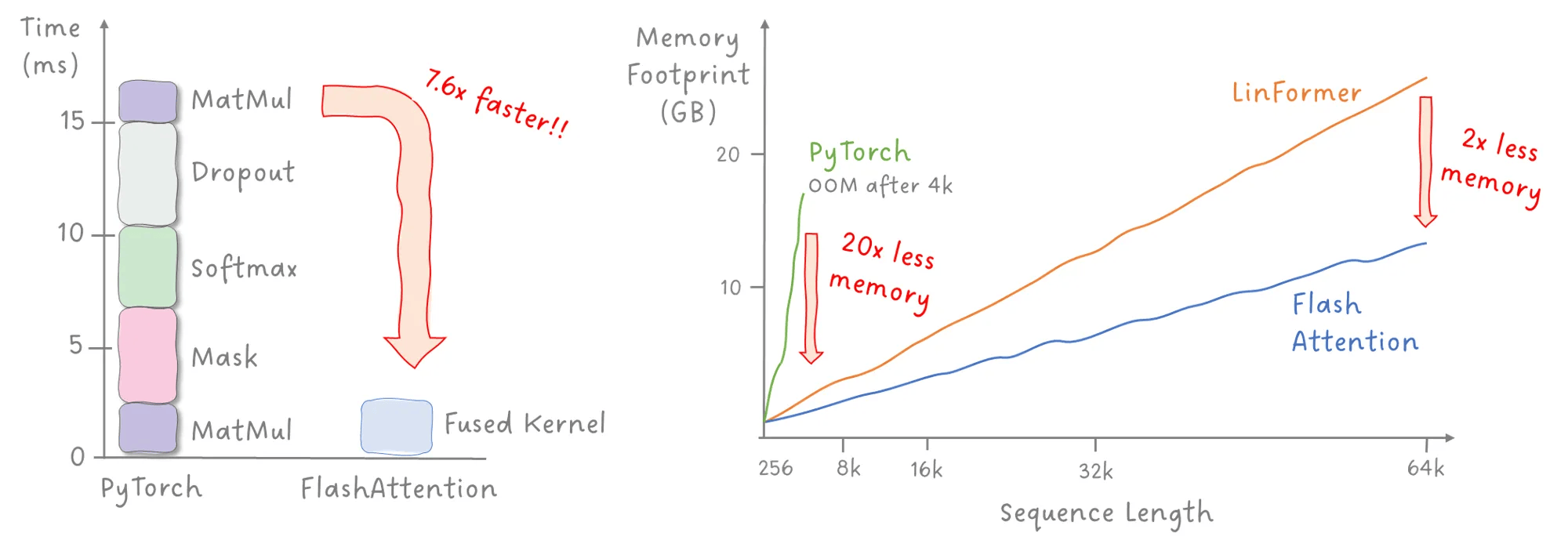
图 2:FlashAttention 相比传统方法的性能提升。图像作者:Sascha Kirch
虽然目前听起来可能还比较抽象,
但 FlashAttention 能带来的具体优势可以非常明确地总结为:
- 更快地训练相同模型;
- 使用更大的 batch 训练相同模型;
- 在相同成本下训练更大(可能性能更好)的模型;
- 支持更长上下文窗口的训练;
- 甚至可以在更小的 GPU 上训练模型。
例如,作者在 OpenWebText 数据集上训练 GPT-2 small 模型:
- 在 8 张 A100 上只需 2.7 天,而不是传统方法的 9.5 天;
- GPT-2 medium 模型只需 6.9 天,传统方法为 21 天。
❓那么,究竟是怎么实现这一切的?
❓我们需要解决哪些关键问题?
让我们继续深入探索吧!🚀
2.1 我们需要解决哪些问题?
正如我们在第一部分中学到的,我们面临的主要问题是:需要在中间过程中读写大量 N×N 的矩阵,这不仅非常耗时,而且消耗大量内存。理想情况下,如果我们可以将 SoftMax 内核与矩阵乘法(MatMul)内核融合,并且只将最终结果写入全局内存,就可以避免这些开销。
但现实是,我们面临两个关键问题,阻止了这种融合的实现:
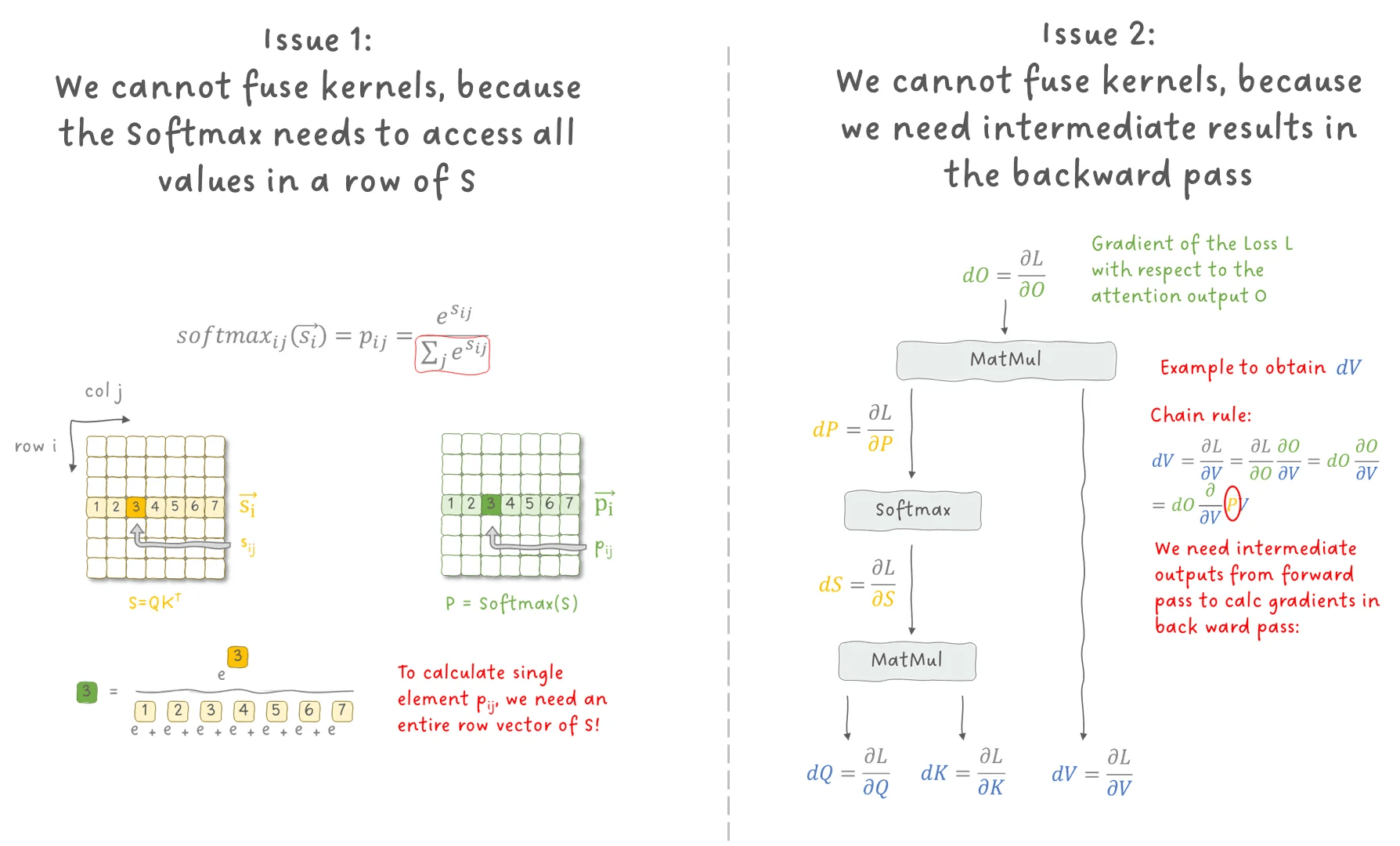
图 3:阻止 Attention 层内核融合的两个关键问题。图像作者:Sascha Kirch
我们从第一个问题开始:SoftMax 操作。
2.2 修复 SoftMax 的问题
回顾第一部分内容:在执行矩阵乘法时,我们通过共享内存对输入进行了切分(chunk),将每一小块加载进来,并通过累计计算得到最终的乘积结果:
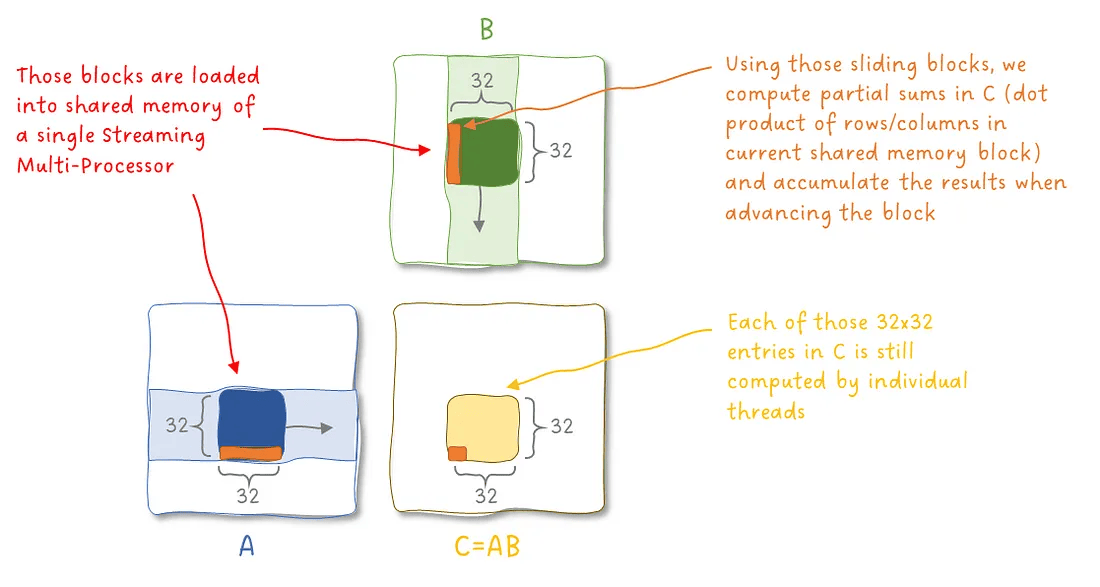
图 4:在矩阵乘法中使用共享内存。图像作者:Sascha Kirch
现在,如果我们希望将 SoftMax 与矩阵乘法内核融合,我们也必须将 SoftMax 的输入进行切块处理,并在每一步迭代中逐步合并这些部分得到最终结果。这正是**SoftMax 操作分解(decomposition)**派上用场的地方。
我们先从标准 SoftMax 的定义开始,并将其改写成论文中更适合实现的形式:
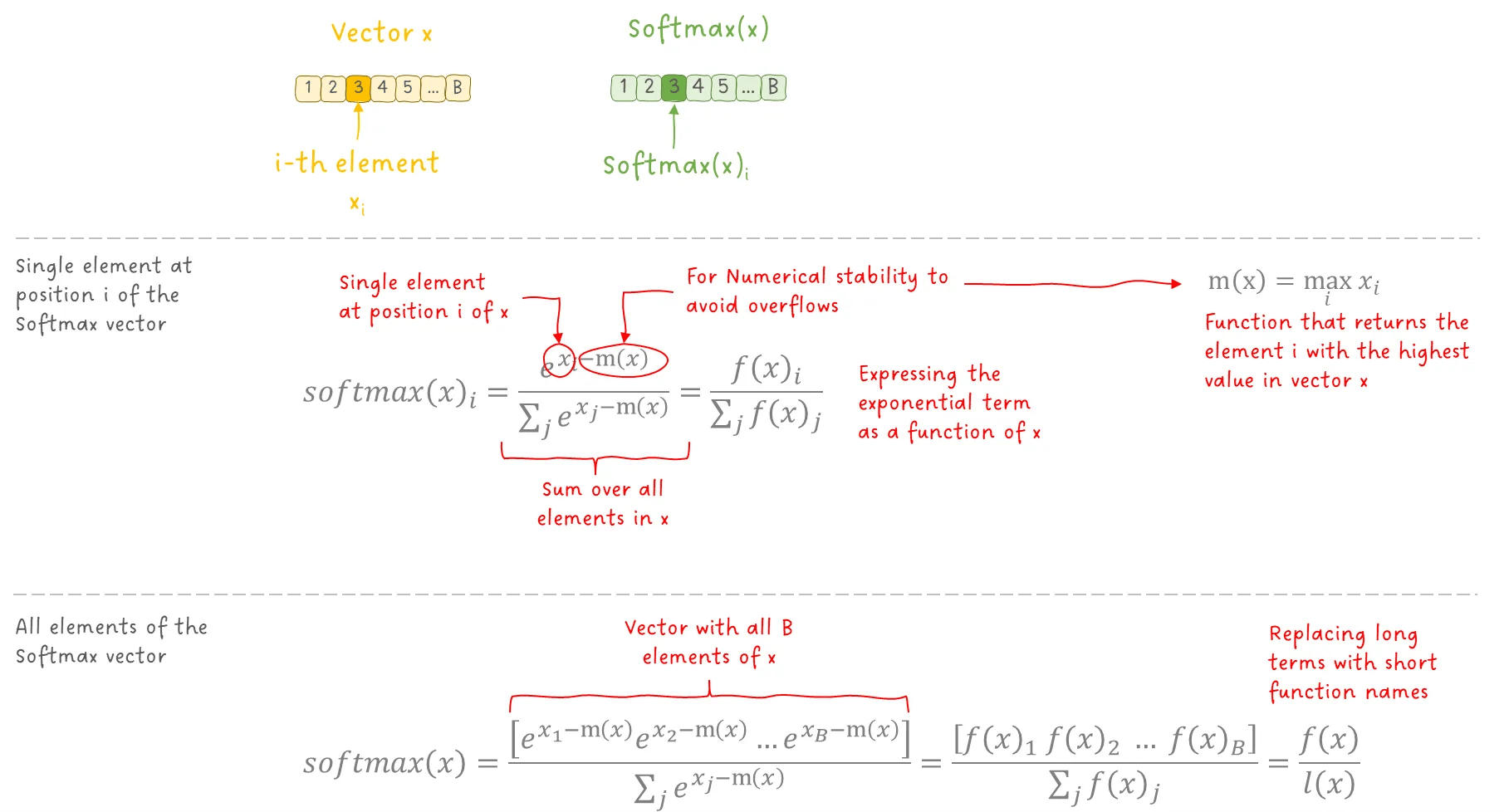
图 5:SoftMax 的数学表达式。图像作者:Sascha Kirch
目前为止,这只是对标准 SoftMax 的重新表达。
❗而现在要进入本系列中最关键的部分之一:
我们将学习如何将 SoftMax 操作进行分解, 使其能分块处理每次只作用于部分输入, 从而使它能够与矩阵乘法内核融合,因为它们将作用于相同的数据块。
设想一下,我们在共享内存中只能存放 xxx 向量的一半,而不是完整向量:

图 6:SoftMax 分解操作中可访问的数据示意。图像作者:Sascha Kirch
重要说明:我们不能直接对每半个向量单独做 SoftMax,
因为为了实现数值稳定性,我们必须知道整个向量 x 的最大值(max(x))。
我们该怎么办?
我们采用以下策略:
- 为每一小块 xxx,我们追踪一些额外的指标(metrics);
- 每一次迭代时,我们: 计算当前块的 SoftMax 部分; 与前面块的结果进行组合; 更新这些额外指标; 更新输出向量。
听起来还是有点抽象?别担心,我们接下来会具体展开。
首先,来看在对向量 xxx 切分为两个块的情况下,SoftMax 如何重新表达:

图 7:SoftMax 分解后的数学公式。图像作者:Sascha Kirch
这些公式可能看起来有点复杂,但请相信我:如果你代入实际数值,会发现这个分解形式与标准 SoftMax 是完全等价的。
为了说明这一点,我亲自做了这个推导演示:

图 8:证明分解后的 SoftMax 等价于标准 SoftMax。图像作者:Sascha Kirch
❓那么,我们从中得到了什么?
核心洞察在于:
我们可以先对 xxx 的第一个块计算 SoftMax, 然后对第二个块计算, 再将它们重新缩放并合并,得到完整向量 xxx 的正确 SoftMax 结果。
注意,函数 m(x) 和 l(x) 是需要对整向量 xxx 有全局信息的。
因此我们:
- 将它们缓存在全局内存中;
- 并在每次迭代中对其进行更新。
这样做的两个目的:
- 在后续迭代中用于更新和缩放中间结果;
- 在反向传播阶段避免重新计算它们,从而节省计算。
🎯 现在你可能还是觉得有点抽象,没关系!
我们已经谈了很多“迭代”这个词,是时候进入更具体的内容了:
现在我们来展示 FlashAttention 中的前向传播算法(Forward Pass)!
2.3 前向传播(The Forward Pass)
在我们深入具体细节之前,先从高层次的执行流程开始了解 FlashAttention 的前向传播是有意义的。我们将通过图示来说明算法是如何迭代处理数据的。
仅仅通过这一步,你就能理解整个算法的一大核心部分。
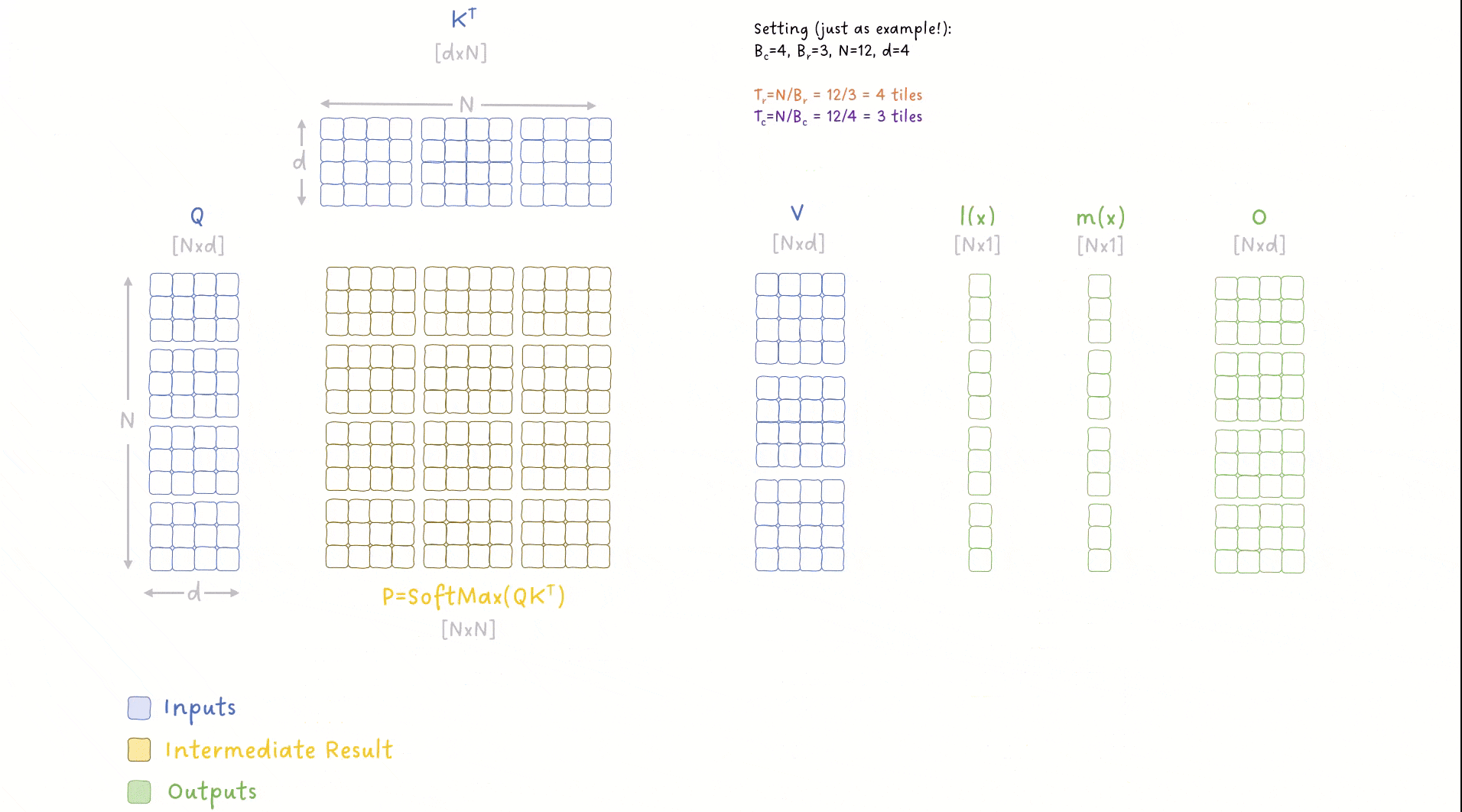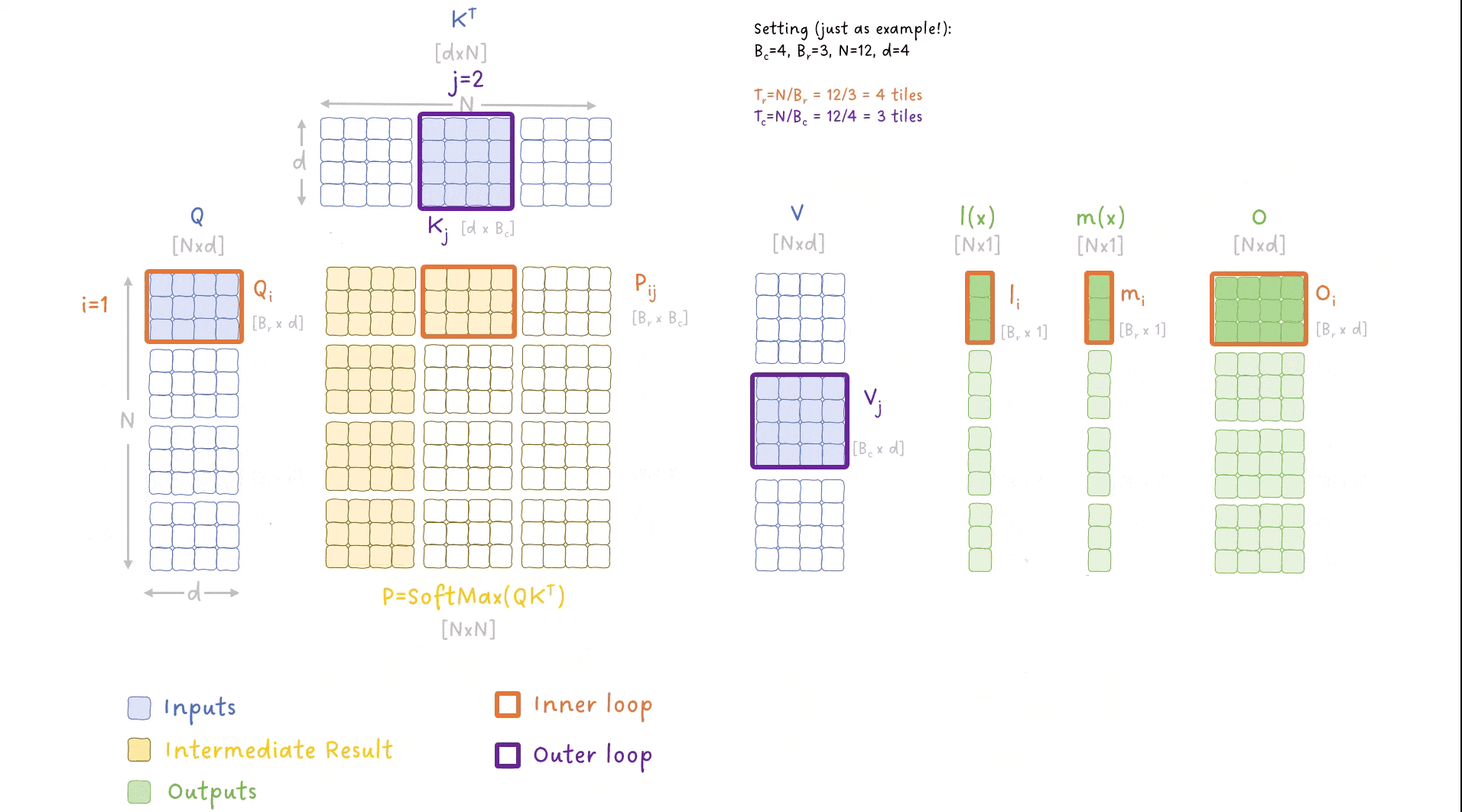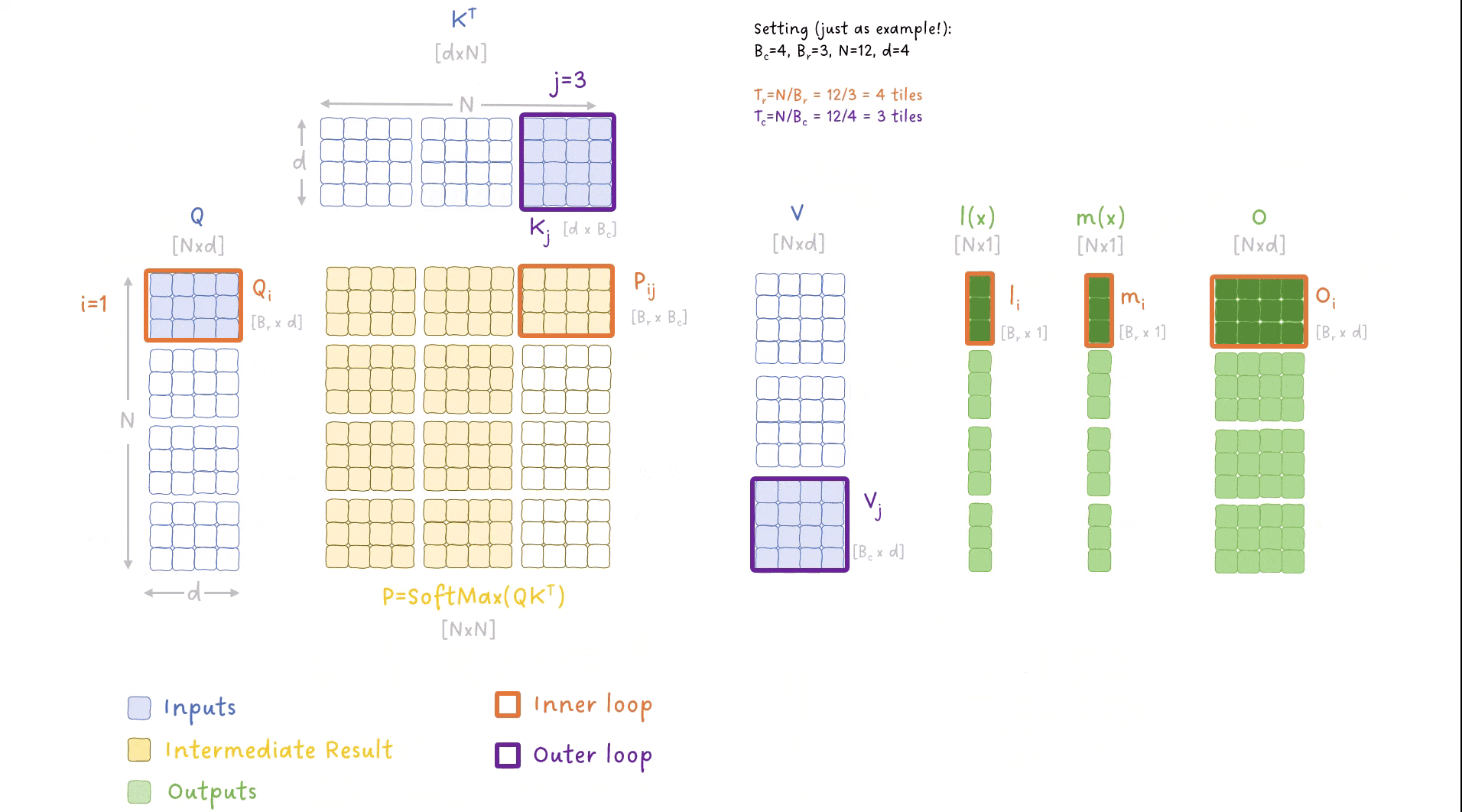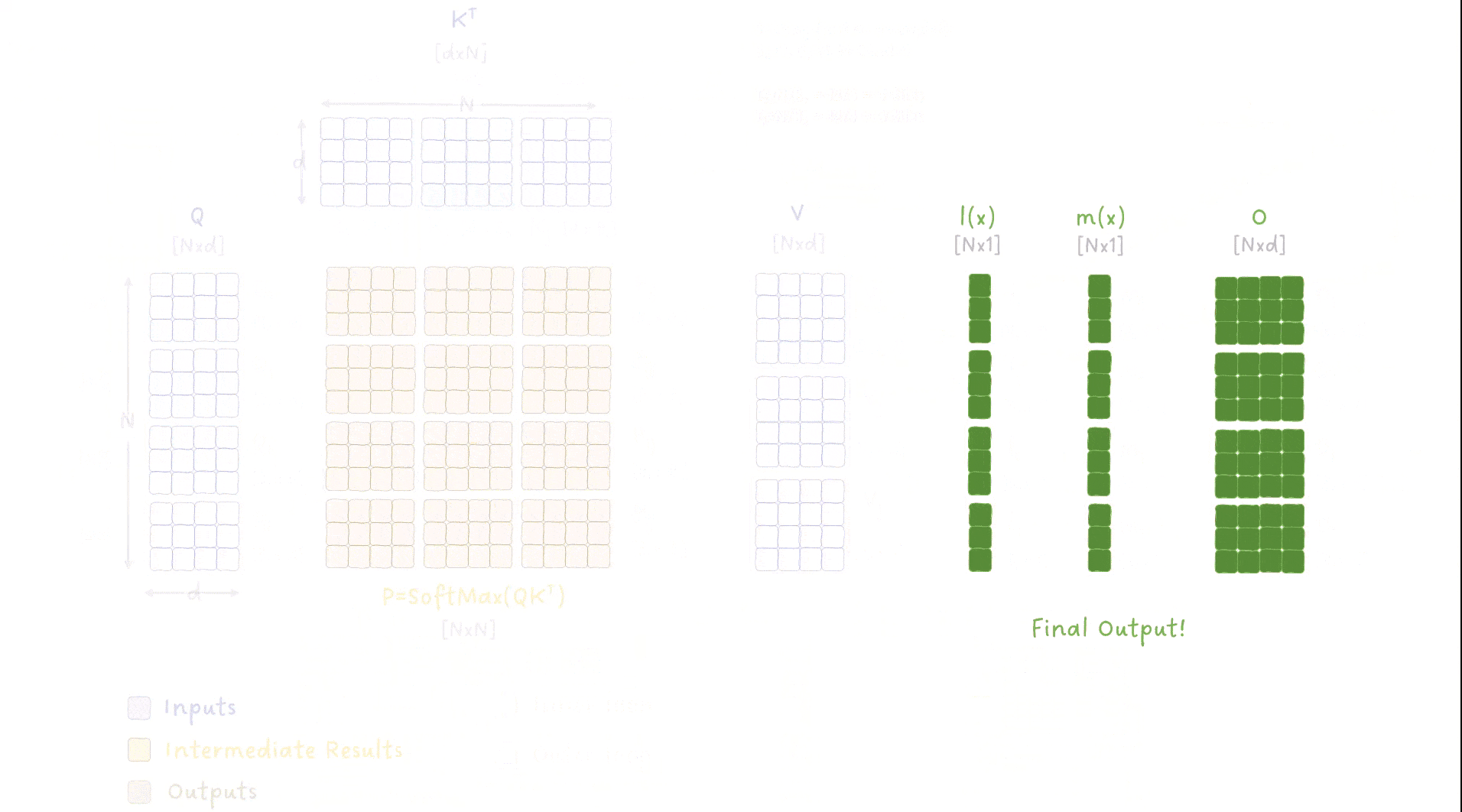
图 9:FlashAttention 算法中外层和内层循环如何遍历数据的动画演示。图像作者:Sascha Kirch
这张图内容很多(老样子,有点密集 😅),但你需要理解以下关键点:
我们对输入数据进行了两个层级的循环:
- 外层循环:遍历 Key 和 Value 的数据块(chunk),索引为 j;
- 内层循环:遍历 Query 的数据块,索引为 i;
其他重要细节包括:
- 对输出矩阵 O 进行了多次迭代更新,每次外层循环都更新一部分;
- 对 SoftMax 中涉及的指标 m(x) 和 l(x) 进行了持续追踪与迭代更新;
- 我们从不将完整的 N×N 矩阵写入全局内存,而是仅将小的块存在共享内存中,最终只把结果写入全局内存;
- 每个 block 对应多行,也即多个 token,因此我们可以并行地计算多个 SoftMax 操作。
理解这张动画,就意味着你理解了 FlashAttention 的核心。
你也开始会明白,它是如何节省时间和内存的。
当然,对于有些人来说到这里可能已经够用了,但我们接下来还会深入剖析具体机制。
接下来,我们具体看看这些分块的中间结果,以及 SoftMax 是如何在这些块上计算的。
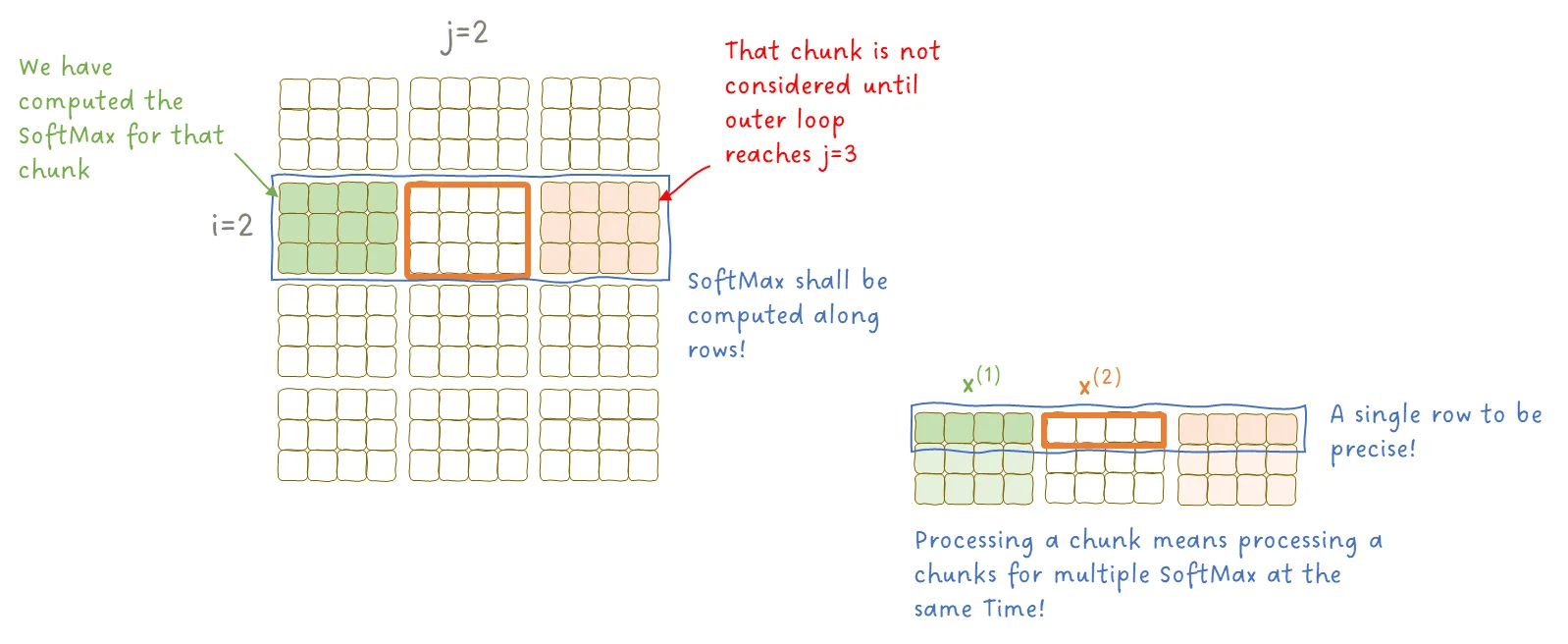
图 10:SoftMax 如何作用于各个数据块。图像作者:Sascha Kirch
在这张图中:
- 内层循环是按行索引 i 迭代;
- 外层循环是按列索引 j 迭代。
还记得吗?SoftMax 是按行计算的,每一行对应一个 token。
所以当我们处理一个数据块时,其实需要同时计算多个 SoftMax;
而随着外层循环的推进,我们需要用前一个数据块 x(1) 的 SoftMax,更新当前数据块 x(2) 的计算结果。
有了这些知识后,我们可以来看 FlashAttention 论文中实际的前向传播算法(稍后我们会解释初始化和更新步骤的细节):

图 11:FlashAttention 的前向传播算法。图像作者:Sascha Kirch
你可以试着将上图与之前的动画对照理解。
特别值得注意的是:
这个算法融合了两个矩阵乘法内核和一个 SoftMax 内核,且从不向全局内存写入 NxN 矩阵。
你可能会问:
“那如果我们没有中间结果,在反向传播中怎么计算梯度呢?”
这个我们马上就会讲到。但在此之前,我们先把前向传播的内容讲完整。
让我们仔细看看算法中的第 6–11 步:这是在计算当前块的 SoftMax,并更新 SoftMax 所需的两个指标 m(x) 和 l(x)。
此时,我们已经完成:
- Q⋅K 的矩阵乘法;
- 当前数据块的 m(x) 和 l(x) 计算;
- 并将其与之前的数据块的指标合并,得到更新后的指标。
接下来,在第 12 步中,我们使用当前块和更新后的指标来更新输出矩阵 OOO。
这一步稍微有点复杂,因为它融合了 SoftMax 内核与 P⋅V 的矩阵乘法内核。
我们来看这一步的细节:
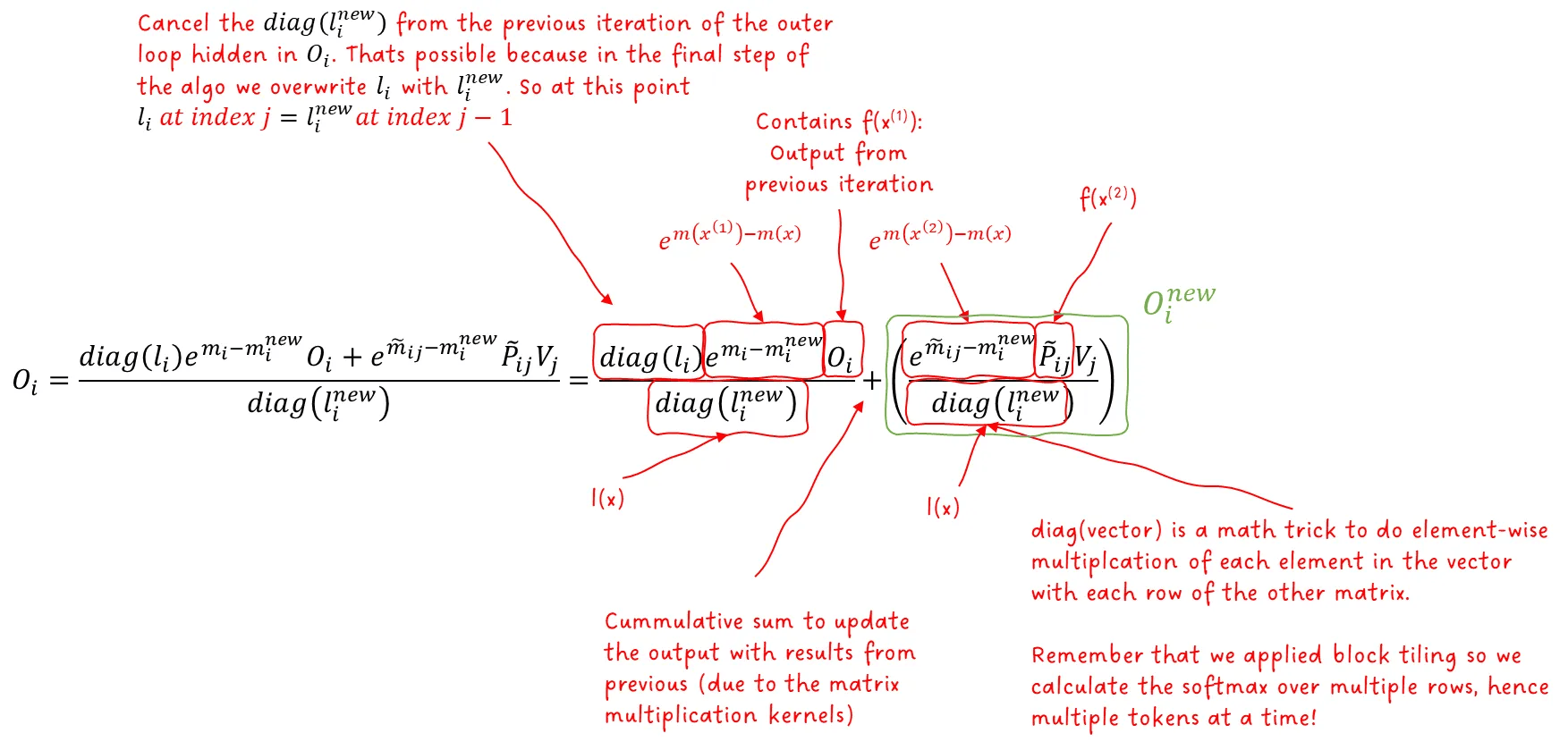
图 13:解释 FlashAttention 内层循环中的输出更新公式。图像作者:Sascha Kirch
图中用到了 diag(vector) 操作:它会构建一个对角矩阵,对角线为给定向量,其余元素为零。
这个技巧的作用是:将矩阵的每一行乘以对应的向量元素 —— 因为每一行代表一个 token,所以每一行要分别做 SoftMax。
再次强调:这个递归式更新加上内核融合,确实让人一开始难以理解 😅。
但如果你把数值代进去认真计算,会发现一切是闭合且合理的。
还有一点我们没讲:
在算法的第 2 步中,指标 m(x)、l(x) 以及输出矩阵 O 是如何初始化的?
因为 O,m(x),l(x) 是递归更新的,
所以第一次迭代时我们必须考虑一个初始情况(base case)。
因此我们初始化方式如下:
- O 和 l(x):初始化为 0;
- m(x):初始化为 负无穷。
如果你将这些初值代入我们之前讲的 SoftMax 分解公式,
你会发现结果等价于对第一个数据块进行标准 SoftMax 操作。

图 14:解释为什么和如何进行这些初始化。图像作者:Sascha Kirch
现在只剩下最后一步:
运行整个算法,输出最终的 N×dN \times dN×d 输出矩阵 OOO。
🎉 这就是 FlashAttention 的前向传播!
太棒了,你能坚持看到这里!
接下来,让我们来讲一讲大多数博客文章都忽略的部分:
反向传播(Backward Pass) —— 也就是计算梯度、更新模型参数的部分。
顺便提一句:你知道 FlashAttention 的作者 Tri Dao 也是 Mamba 状态空间模型(Mamba SSM) 的作者之一吗?
Mamba 是 Transformer 的替代方案,能将计算复杂度从 O(N^2) 降低为线性!
2.4 反向传播(The Backward Pass)
通常来说,反向传播并不是什么难事——那为什么我们还要专门讲这一部分呢?原因有两个:
- 我们在前向传播中为了节省内存和时间, 省略了中间结果的保存,但这些结果对于计算梯度来说是必要的;
- 反向传播中我们也不希望生成巨大的 N×N 矩阵, 所以我们同样需要使用融合内核(fused kernel),并依赖共享内存完成计算。
幸运的是,反向传播的算法和前向传播非常相似——我们依然会在内层循环和外层循环中遍历相同的数据块。
那么,前向传播中缺失的中间结果怎么办?
其实,我们可以在反向传播中动态重新计算它们。
别忘了,GPU 的计算核心运行速度远快于读写全局内存的速度。
所以哪怕我们在反向传播中重复计算了一遍前向传播的中间结果,
依然比将它们写入并从全局内存中读取要高效!
实际上,我们并不需要全部重新计算:
还记得我们把 SoftMax 的指标 m(x) 和 l(x) 保存在全局内存中了吗?我们可以用它们来直接计算当前块的 SoftMax 值,这一次计算结果就是准确的。
在正式进入算法之前,我们先来理解一下需要计算哪些内容。
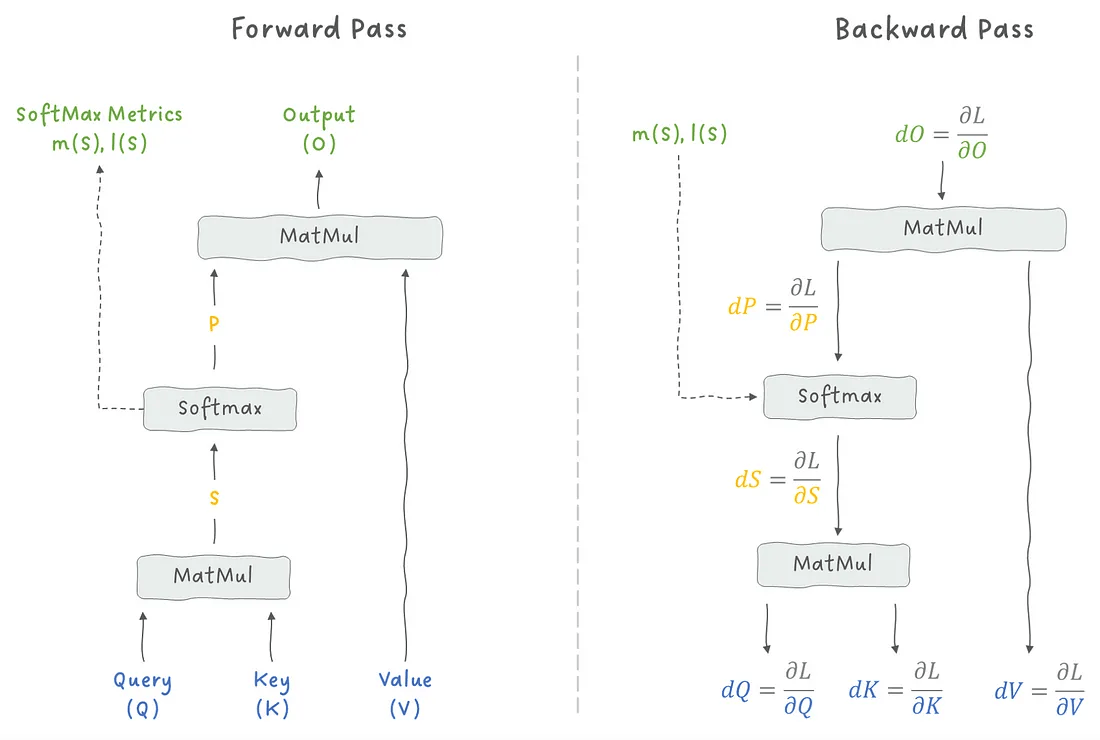
图 15:Attention 层中前向传播与反向传播的对比。图像作者:Sascha Kirch
我们需要根据损失函数计算模型参数的梯度。
这要通过**链式法则(chain rule)**逐步计算每个中间变量的梯度,直到得到损失函数关于输入矩阵 Q、K 和 V 的梯度。
正如我导师常说的那样:“这是练习,不是惩罚 😄”,所以我们把这些梯度推导列出来。
但在开始推导之前,有几个关键点你需要注意:
- SoftMax 是按行计算的, 所以我们也必须逐行计算梯度;
- 梯度符号 dV 表示的是 ∂L/∂V,即损失函数对矩阵 V 的偏导数;
- 我们仍然使用分块计算,所以要考虑数据分块和共享内存的访问方式。
我们“从简单的地方开始”,应用链式法则,看看有哪些梯度是我们必须计算的:
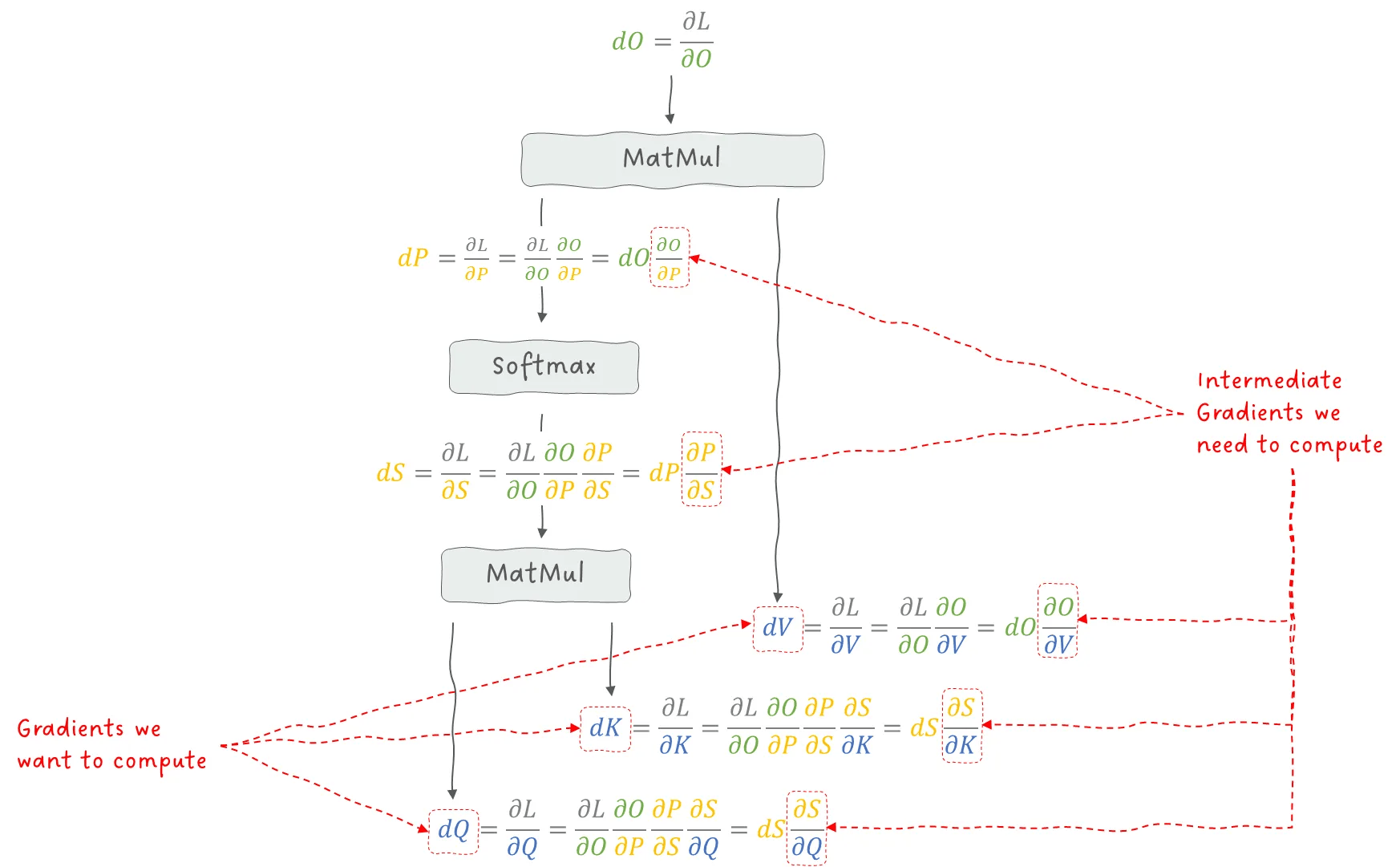
图 16:Attention 层反向传播中使用链式法则推导梯度。图像作者:Sascha Kirch
接下来,我们逐步计算每一项梯度。我们从矩阵乘法 O=P⋅V 开始。

图 17:反向传播第 1 步:P 与 V 的矩阵乘法。图像作者:Sascha Kirch
通过这一步,我们可以得到第一个需要的梯度:dV。
很多人在这里会困惑:如何对矩阵求导?为什么有时候要转置?
简单的规则是:
- 如果你对矩阵乘法的第一个矩阵求导,梯度(dO)从左边乘上;
- 如果你对第二个矩阵求导,梯度(dO)从右边乘上。
接下来我们要计算 dK 和 dQ,这需要反向传播穿过 SoftMax 和 Q⋅K 的矩阵乘法。
首先来看 SoftMax 部分。
还记得,SoftMax 是按行计算的,每一行对应一个输入 token。
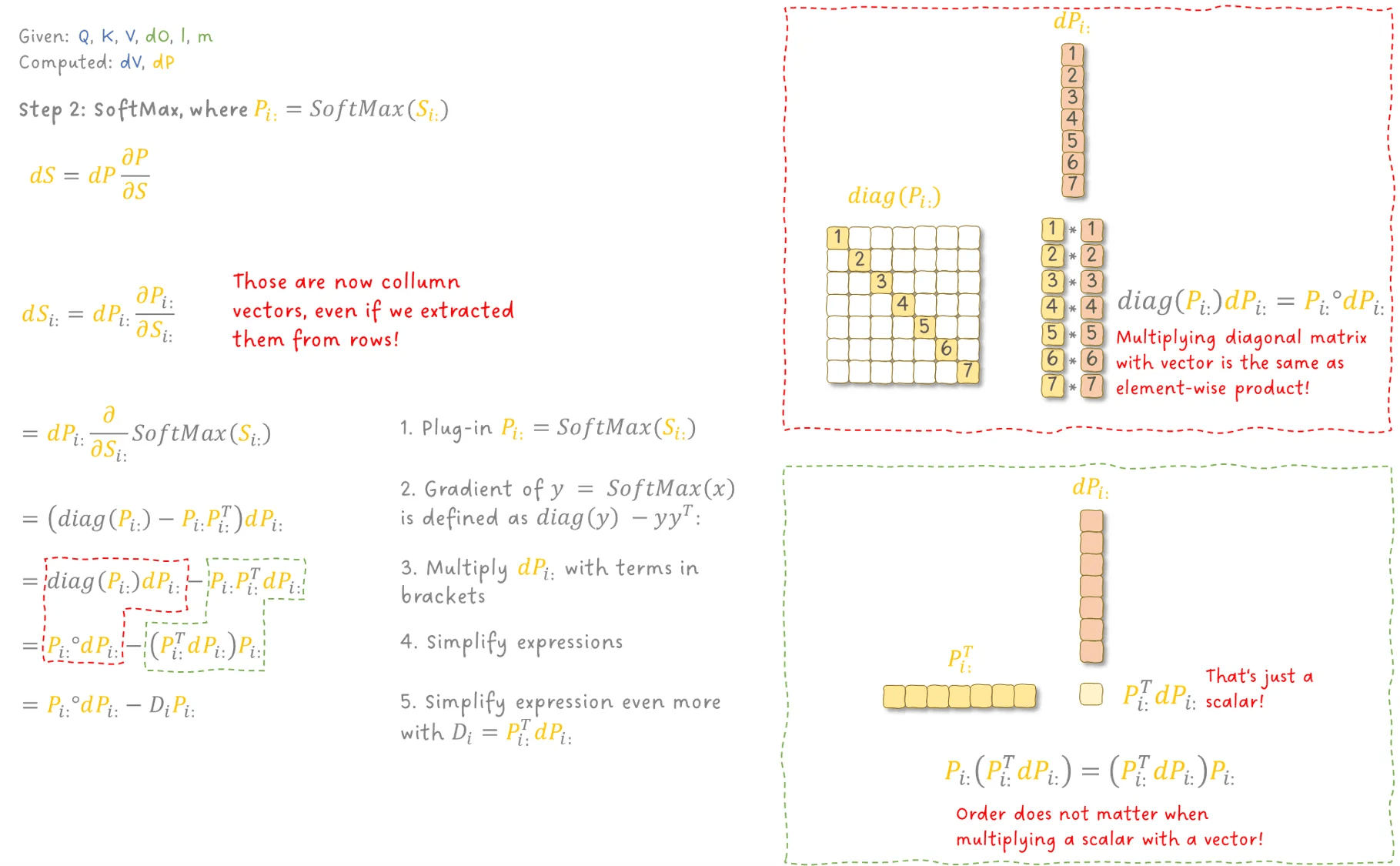
图 18:反向传播第 2 步:SoftMax 操作。图像作者:Sascha Kirch
通过一些代数技巧,我们可以得到每一行的梯度 dS,将所有行的梯度拼接起来,就得到了完整的 dSdSdS。现在有了 dSdSdS,我们就可以计算 Q⋅K 的梯度,进一步得到 dQ 和 dK。

图 19:反向传播第 3 步:获得 dQ 和 dK。图像作者:Sascha Kirch
至此,我们已经计算出了 Attention 层中所有需要的梯度:
- dQ
- dK
- dV
这些就可以继续向后传播(backpropagate),用于更新模型参数。不过,在看论文中的完整算法前,我们还需要注意一件事:由于我们仍然采用 块切分(tiling) 和 共享内存中的迭代计算,每次迭代我们只能访问一小部分数据,因此我们需要在每次内层循环中重新计算中间结果。
好消息是:我们仍然保留了 m(x) 和 l(x),所以可以准确地重新计算每一块的 SoftMax,而无需再次迭代更新这些指标。
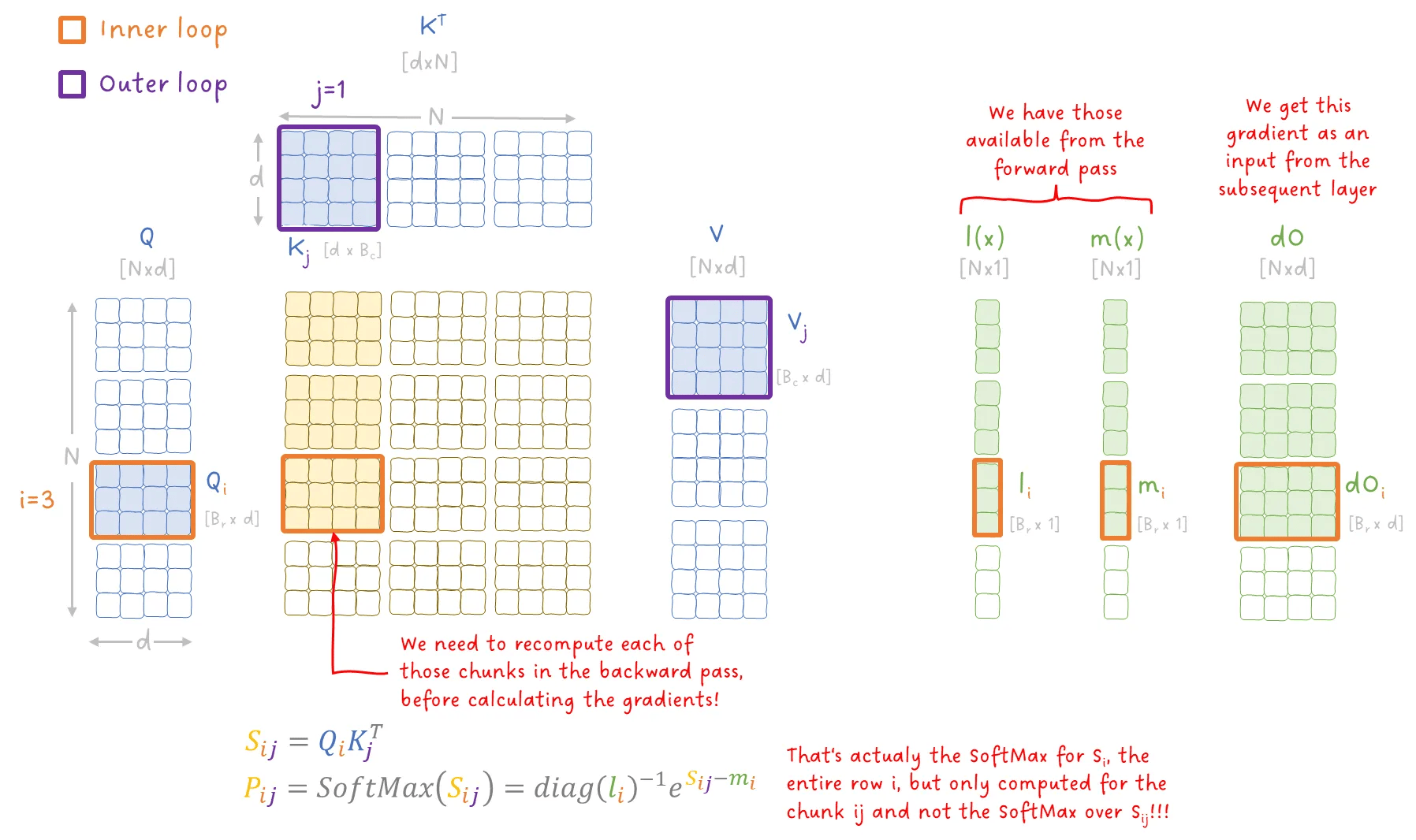
图 20:FlashAttention 反向传播中中间结果的重计算。图像作者:Sascha Kirch
现在,终于可以介绍论文中完整的 反向传播算法 了!请注意:该算法也覆盖了 Masking 和 Dropout 操作,为了聚焦重点,我们在前面简化时故意省略了它们。

图 21:FlashAttention 的反向传播完整算法。图像作者:Sascha Kirch
🎉 至此,FlashAttention 的反向传播算法已完整介绍完毕!
让我们快速总结一下这一部分的收获:
我们讲解了:
- 为什么反向传播中也不能生成大型中间矩阵;
- 如何利用前向传播保存下来的指标 m(x) 和 l(x);
- 如何使用链式法则推导 Attention 层中的所有梯度;
- 如何在块状共享内存中重新计算中间结果;
- 最终如何完成整个反向传播计算!
3. 第二部分总结(Wrapping Up Part 2)
哇,这一趟旅程可真不轻松,对吧?😅
但你坚持到了最后,太棒了!
FlashAttention 的核心思想其实很简单:
将 Attention 层中的所有内核(kernels)进行融合,避免将庞大的 N×NN \times NN×N 矩阵写入全局内存。
为了实现这一目标,我们必须解决两个关键问题:
- 对 SoftMax 操作进行分解,使其可以在输入矩阵的小块(chunk)上独立应用;
- 在反向传播中重新计算中间结果,而无需物化(materialize)庞大的 N×N 矩阵。
在这一部分中,我们真正花时间深入探讨了算法的细节,并理解了它是如何运作的。
感谢阅读!🙌