在 MLCEngine 中优化和描述高吞吐量低延迟 LLM 推理
mlc-llm框架对比vllm等一系列测试说明。
前言
6 月,发布了MLCEngine,这是一款由机器学习编译驱动的通用 LLM 部署引擎。MLCEngine 构建了一个单一引擎,可在云端和边缘设备上实现 LLM 部署,并全面支持 OpenAI API。
性能一直是我们发展的关键驱动因素之一。在过去两个月里,MLC 社区一直在努力提高服务器设置的推理性能。这篇文章分享了我们在此过程中的成果和经验。
这篇文章特别关注高吞吐量低延迟的 LLM 推理问题。虽然许多性能改进都集中在面向吞吐量的设置上,但延迟对于 LLM 引擎来说变得越来越重要。我们特别感兴趣的是每个用户可以获得超过 50 tok/秒、100 tok/秒甚至更高的速度,同时保持合理的请求并发性(批处理大小)以获得更高的吞吐量。此外,我们有兴趣在改变请求并发性时研究吞吐量-延迟权衡,为用户提供更灵活的选择,以选择最适合他们的设置。
在本文的剩余部分,我们首先评估 MLCEngine 在 Llama3 模型上的延迟和吞吐量。然后,我们将进一步深入分析不同推理设置(例如张量并行和推测解码)对高性能、低延迟推理的影响。
我们在 H100 上的结果表明,MLCEngine在多个延迟约束阈值的低延迟推理设置上带来了最先进的性能。我们还将针对低延迟推理场景提供不同推理系统设置权衡的特征。
基准测试设置
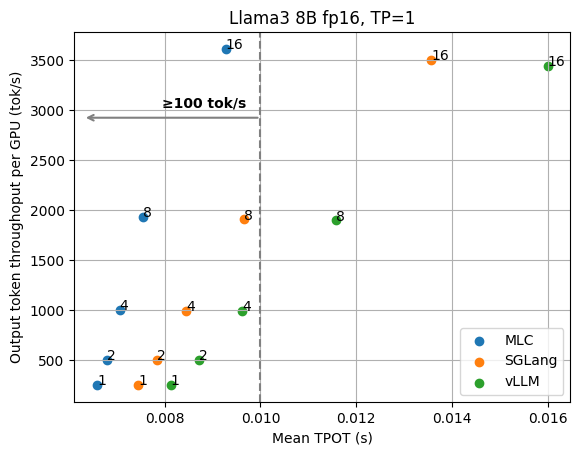
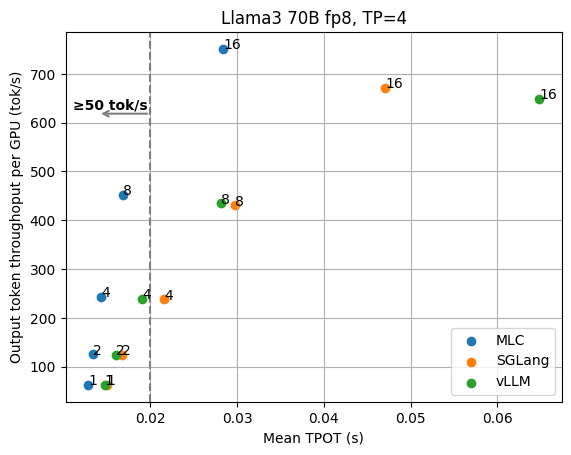
本博文中的评估是在配备 NVIDIA H100 SXM GPU 的节点上使用 Llama3 8B fp16 和 70B fp8 进行的。我们使用ShareGPT 数据集构建请求输入并设置输出长度。在评估中,我们将并发请求数固定为 1/4/8/10/16/20/30/64,总共发送 500 个请求。我们测量每个请求的 TPOT(每个输出令牌的时间,即收到第一个令牌后每秒收到的平均令牌数)和整体引擎输出令牌吞吐量。我们在附录中提供了更多结果和讨论,涉及请求率、TTFT(第一个令牌的时间)、第 90 百分位性能和其他输入/输出长度的固定主题。附录中还提供了重现基准测试结果的说明。
为了了解 MLCEngine 与当前最先进的解决方案相比如何,我们将其与 SGLang (v0.3.1.post2) 和 vLLM (v0.6.1.post2) 进行了比较。LLM 推理领域正在快速发展,因此我们也预计框架会随着时间的推移而改进。我们将在博客中花一部分时间讨论可能使更广泛的 ML 系统社区受益的经验教训。
基准吞吐量和延迟权衡
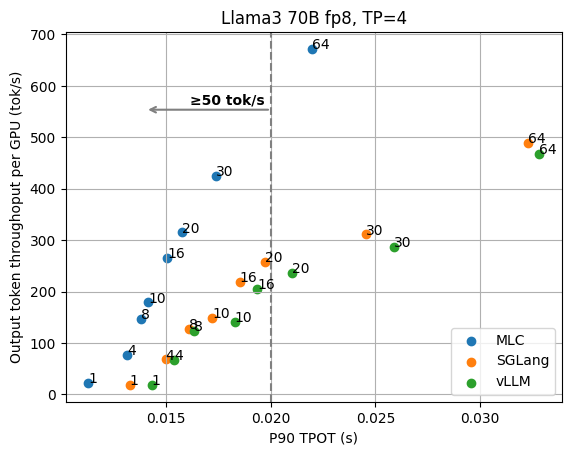
我们从 1 个 GPU 上的 Llama3 8B fp16 模型和 4 个 GPU 上的 70B fp8 模型的基本结果开始,这些模型都具有张量并行性。下图显示了不同并发请求数下的 TPOT(每个输出令牌的时间)和每个 GPU 的输出令牌吞吐量。我们根据 GPU 数量对吞吐量进行标准化,因为我们始终可以添加 GPU 副本来扩展整体吞吐量。这些数字不包括稍后讨论的其他优化(例如推测解码),并且所有数据点都是使用相同的 API 端点收集的,无需进行特殊的配置调整。
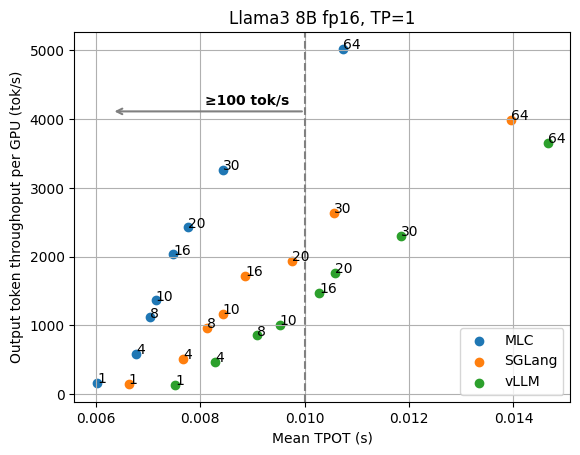
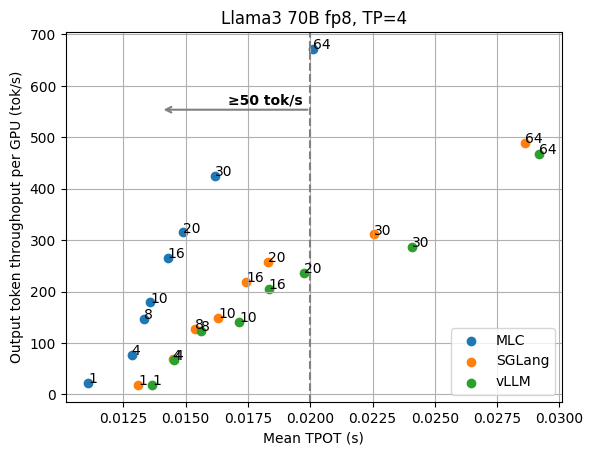
从图中我们可以清楚地看到延迟和输出吞吐量之间的权衡。在以吞吐量为导向的设置中,我们通常关注图的右侧,随着请求并发性的增加,LLM 引擎可以实现更高的吞吐量,因为并发请求被批量处理。
但是,当我们考虑低延迟目标(比如说,我们希望输出令牌优于 100 tok/秒)时,我们需要查看符合延迟目标的图的左上角。例如,为了保持 Llama3 8B 的 100 tok/秒延迟,MLCEngine 可以维持大约 30 个并发用户,并获得 3000 tok/秒的总吞吐量。总体而言,我们发现 MLCEngine 可以在低延迟推理设置上实现最先进的性能,并且在我们扩展到更大的工作负载时继续保持有效。在下一节中,我们将讨论该方案背后的技术。
我们如何实现低延迟?
多种因素导致 MLCEngine 的低延迟,我们很乐意与社区分享我们学到的经验教训。
快速解码注意力机制。LLM 推理解码阶段注意力机制的计算时间占比随上下文长度而变化,在约 100 个 token 的短上下文中占比不到 20%,而在数千个 token 的长上下文中占比超过 50%。MLC 集成了最先进的注意力库FlashInfer以减少注意力开销。
编译器驱动的内核生成和调度。 作为基于编译器的解决方案,MLCEngine 支持利用来自不同来源的 GPU 内核。例如,我们将 GeMM 运算符调度到 cuBLAS 或 CUTLASS 内核以实现较大的请求并发性,而对于请求并发性为 1 和较低的请求并发性,则使用编译器生成的高效 GeMV 内核。
动态形状感知内存规划和 CUDA Graph。MLC 支持动态形状感知内存规划编译器过程,可帮助静态分配所需的 GPU 内存,从而避免在推理期间进行任何运行时内存分配/释放。我们有 CUDA Graph 重写编译器过程,这进一步使我们能够利用 CUDA Graph 并减少 GPU 内核启动开销。我们发现 CUDA Graph 对于多 GPU 用例尤其重要,可以减少可变性。
减少 CPU 开销。MLC 付出了很多努力来减少连续解码轮次之间的 CPU 开销。重要的是,我们使用独立线程驱动引擎循环,并将所有其他前端请求进程(例如,标记器编码/解码、异步 HTTP 接收/发送等)留在另一个线程上。此架构允许异步处理请求输出和引擎 GPU 计算。与其他 CPU 端优化一起,CPU 开销占批量解码时间的约 3%。
张量并行的影响
数据并行和张量并行是将 LLM 推理扩展到更多 GPU 的两种常用方法。数据并行在额外的 GPU 上复制模型,使整个系统吞吐量翻倍,并保持输出延迟不变。而张量并行使用额外的 GPU 来共同服务模型,减少了服务延迟,但牺牲了一些吞吐量。为了了解张量并行在不同场景中的影响,我们在不同的 TP 设置中评估了 MLCEngine。y 轴按 GPU 数量归一化,因此我们可以有效地比较较高 TP 设置和较低 TP 设置之间的吞吐量延迟权衡。
下图展示了 Llama3 8B fp16 在 1/2 GPU 上的评估结果以及 Llama3 70B fp8 在 4/8 GPU 上的评估结果。
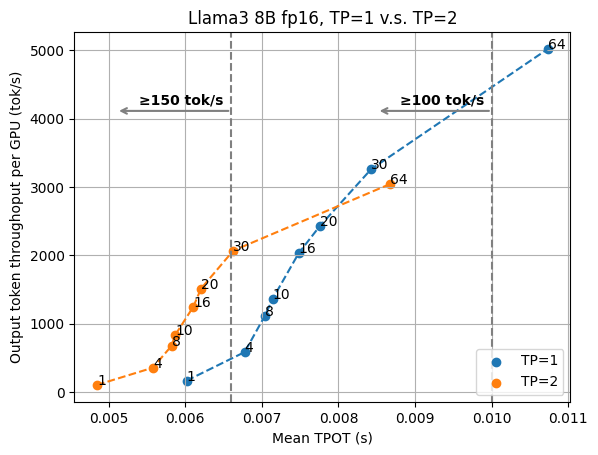
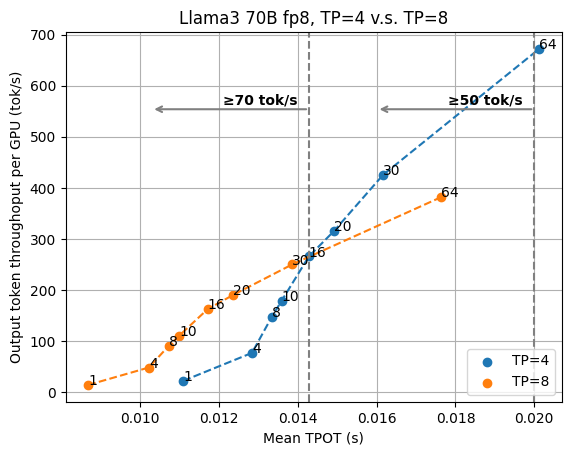
在这两幅图中,我们可以看到两个 TP 设置的曲线之间的交叉点。这意味着我们希望保持较高的 TP 以实现低延迟服务,并在任务对延迟不那么敏感时依赖数据并行性(和较小的 TP 数量)。
对于 Llama3 8B 的情况,如果我们要确保 100 tok/sec 的延迟目标,我们会发现 TP=1 的 30 个请求并发点略高于 TP=2 下的 64 个并发点。但是,由于我们的目标是更低的延迟,因此 TP=2 变得更可取。例如,如果我们进一步将延迟阈值选择为 TPOT 7ms(相当于输出速度为 143 tok/s),对于 TP=2,我们可以选择请求并发 30,但对于 TP=1,我们只能选择请求并发 8,输出吞吐量降低 45%。
对于Llama3 70B fp8,TP=4和TP=8的交叉点是不同的。
这项研究表明,当我们选择具有不同延迟和吞吐量目标的张量并行与数据并行时,会产生复杂的交互,我们需要在决定最佳部署配置时系统地考虑延迟吞吐量权衡。
推测解码的影响
推测解码是 LLM 推理中一种非常有用的技术,可以减少总体延迟。推测解码利用较小的草稿模型(或将草稿提案头合并到模型中)来提出多个标记,并使目标模型一次验证整个草稿,以受益于 LLM 推理的批处理效果。人们可以将推测解码视为一种增加每个并发用户有效批处理大小的方法。到目前为止,大多数推测解码研究都集中在处理单个序列上,而并发性在服务器设置中仍然很重要,因为我们希望获得合理的吞吐量。
我们将推测解码与高性能服务解决方案相结合,并通过 Llama3 70B fp8 推测解码结果与草稿模型 Llama3 8B fp8 和草稿长度 3(因此每个验证步骤的有效长度为 4)对 TP=4 和 TP=8 的研究推测解码的影响,并将结果与正常批量解码进行比较。
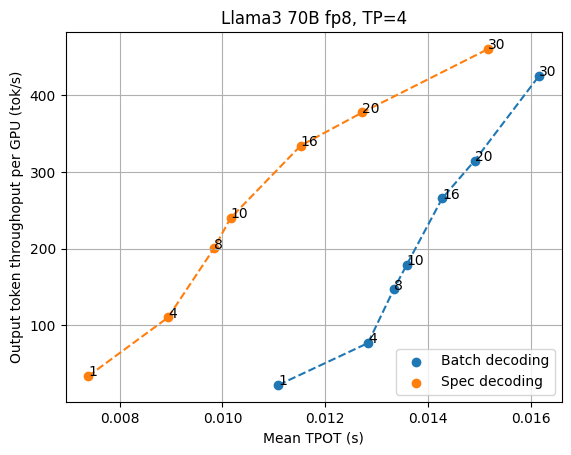
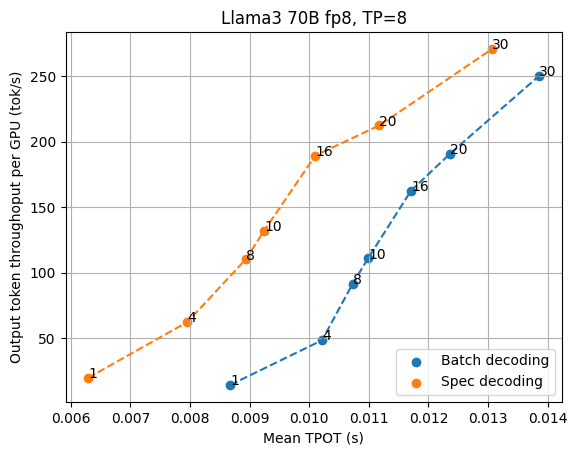
如上图所示,在低延迟设置下,推测解码始终能带来更低的延迟,尤其是当我们希望输出速度超过 70 tok/s 时。在当前的基准测试场景中,TP=4 提供了更好的每 GPU 吞吐量权衡,而 TP=8 提供了尽可能低的延迟。随着请求并发性的增长,正常的批量解码逐渐从内存限制转移到计算限制,从而削弱了推测解码的优势。
值得注意的是,推测解码的好处还取决于推测的接受率,而推测的接受率可能因不同的数据集而有所不同。
具有连续批处理的高效推测解码系统。 值得注意的是,在将推测解码与连续批处理相结合时,我们需要处理复合系统复杂性。由于草稿模型仍在紧密循环中运行,并且可能受到引擎开销的严重影响,因此减少 LLM 引擎开销变得极为重要。我们还需要仔细管理草稿逻辑,并尽可能避免动态内存分配。最后,我们需要构建一个专门的内核来一次性验证所有批处理提案,而无需返回 CPU。
讨论和未来机会
在这篇博文中,我们研究了 LLM 推理在高吞吐量低延迟场景中的权衡。值得注意的是,我们尚未介绍 MLCEngine 中的其他高级功能,例如前缀缓存(影响常见的系统提示)、结构化约束开销(用于 JSON 模式生成)以及 Eagle 和 Medusa 等高级推测方法。这些元素的复合效应可能取决于我们正在研究的场景以及相应系统解决方案的有效性。我们将在以后的文章中介绍这些研究。
附录
修复请求率
到目前为止,评估主要集中在固定请求并发性上,这可以准确地揭示底层 LLM 引擎在不同工作负载重量下的性能。固定请求率是另一种常见的基准工作负载。当以固定请求率运行 LLM 引擎时,引擎的底层批处理大小会随时间而变化。与固定请求并发性相比,使用固定请求率进行基准测试可以提供更全面的结果,后者更为细化。下图显示了不同固定请求率(1/2/4/8/16)下的结果,其中 MLCEngine 提供了最先进的对齐延迟。
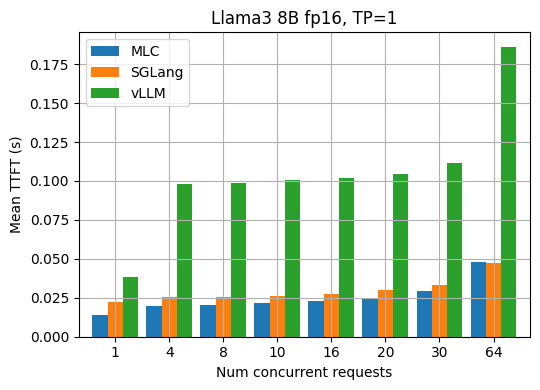
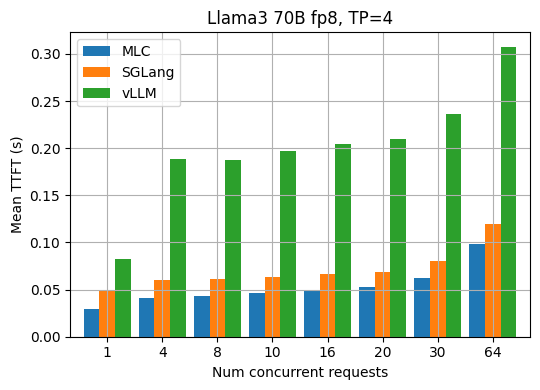
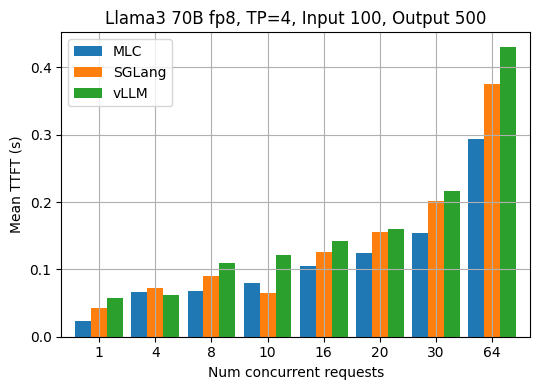
第一个 token 的时间
TTFT(第一个 token 时间)是 LLM 推理中的一个重要指标。它指的是从向 API 发送请求到收到响应的第一个 token 之间的时间(以秒为单位)。通常,TTFT 指标揭示了 LLM 引擎的请求调度和输入预填充的效率。下图显示了 Llama3 8B fp16 和 70B fp8 型号在不同请求并发下测得的平均 TTFT。MLCEngine 在各种请求并发下通常具有可比的对齐 TTFT。
90% 的表现
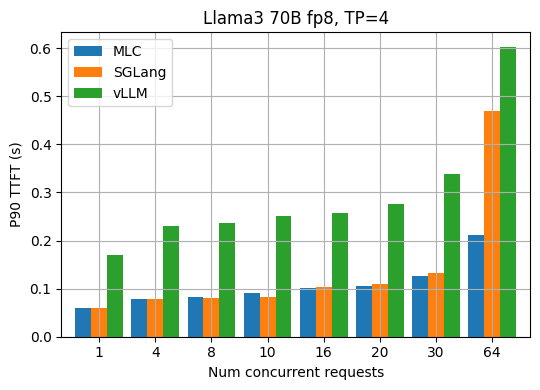
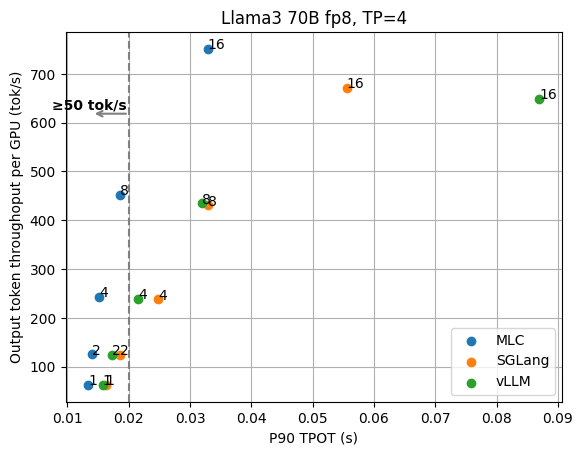
除了平均性能之外,尾部性能(TPOT、TTFT)也是大家关心的重要指标,下面两张图分别是Llama3 70B fp8在不同请求并发度下的p90 TPOT和TTFT结果。
下面两张图分别是不同固定请求率下的p90 TPOT和TTFT。

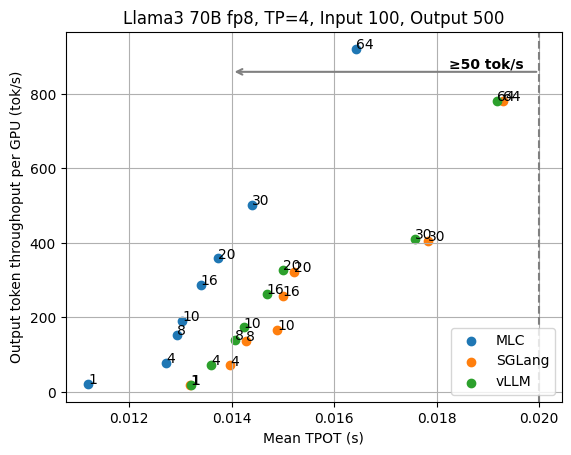
不同的输入/输出长度
除了重复使用 ShareGPT 数据集中的输入和输出长度外,我们还评估了具有其他固定输入/输出长度的 LLM 引擎。下图显示了当每个请求的输入长度固定为 100 且输出长度固定为 500 时,Llama3 70B fp8 的 TPOT 和 TTFT 结果。
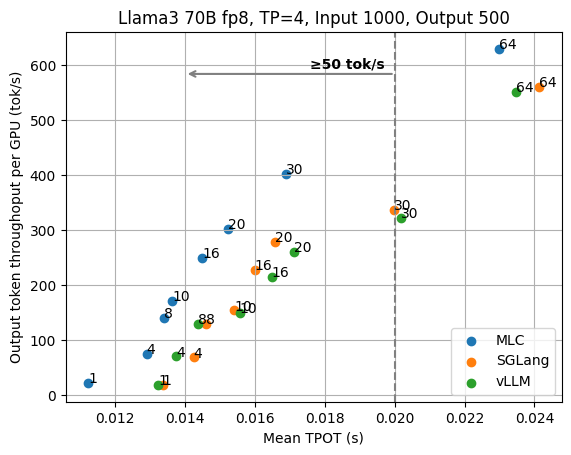
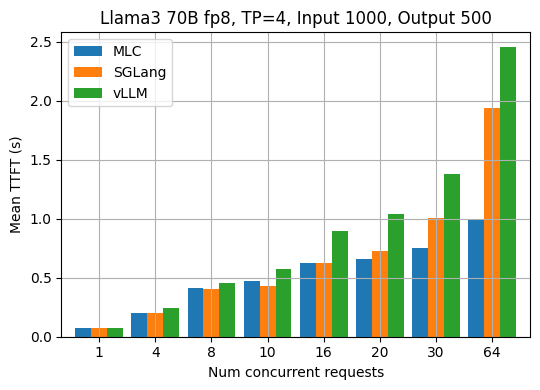
下面两张图分别显示了固定输入长度为 1000、输出长度为 500 的结果。
基准测试说明
# Install MLC-LLM
python3 -m pip install --pre -U -f https://mlc.ai/wheels mlc-llm-cu123 mlc-ai-cu123
export SERVER_ADDR="127.0.0.1"
export SERVER_PORT="8000"
# Llama3 8B
## Launch a server
python3 -m mlc_llm serve HF://mlc-ai/Llama-3-8B-Instruct-q0f16-MLC \
--mode server --host $SERVER_ADDR --port $SERVER_PORT --device cuda \
--prefix-cache-mode disable --enable-debug
python3 -m sglang.launch_server --model meta-llama/Meta-Llama-3-8B-Instruct \
--host $SERVER_ADDR --port $SERVER_PORT --dtype float16 \
--disable-radix-cache --enable-torch-compile --trust-remote-code
python3 -m vllm.entrypoints.openai.api_server --model meta-llama/Meta-Llama-3-8B-Instruct \
--host $SERVER_ADDR --port $SERVER_PORT --dtype float16 \
--disable-log-requests --trust-remote-code --num-scheduler-steps 10
## Run benchmark
wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
export SHAREGPT_PATH=$PWD/ShareGPT_V3_unfiltered_cleaned_split.json
export MODEL_PATH=/path/to/Meta-Llama-3-8B-Instruct
export API_ENDPOINT=mlc # Or "sglang"/"vllm"
python3 -m mlc_llm.bench --api-endpoint $API_ENDPOINT --dataset sharegpt --dataset-path $SHAREGPT_PATH \
--tokenizer $MODEL_PATH --num-request 500 --num-gpus 1 \
--num-concurrent-requests 1,4,8,10,16,20,30,64 \
--temperature 0.6 --top-p 0.9 --ignore-eos --apply-chat-template \
--host $SERVER_ADDR --port $SERVER_PORT
# Llama3 70B
## Compile model for MLC
git clone https://huggingface.co/mlc-ai/Llama-3-70B-Instruct-fp8-MLC
### This step may take about 10 min.
python3 -m mlc_llm compile ./Llama-3-70B-Instruct-fp8-MLC \
--device nvidia/nvidia-h100 --opt O3 --overrides "tensor_parallel_shards=4" \
-o ./Llama-3-70B-Instruct-fp8-MLC/lib.so
## Launch a server
python3 -m mlc_llm serve ./Llama-3-70B-Instruct-fp8-MLC --model-lib ./Llama-3-70B-Instruct-fp8-MLC/lib.so \
--mode server --host $SERVER_ADDR --port $SERVER_PORT --device cuda \
--prefix-cache-mode disable --enable-debug
python3 -m sglang.launch_server --model neuralmagic/Meta-Llama-3-70B-Instruct-FP8 \
--host $SERVER_ADDR --port $SERVER_PORT --dtype float16 \
--disable-radix-cache --trust-remote-code --tp 4
python3 -m vllm.entrypoints.openai.api_server --model neuralmagic/Meta-Llama-3-70B-Instruct-FP8 \
--host $SERVER_ADDR --port $SERVER_PORT --dtype float16 \
--disable-log-requests --trust-remote-code --tensor-parallel-size 4 --num-scheduler-steps 10
## Run benchmark
export SHAREGPT_PATH=$PWD/ShareGPT_V3_unfiltered_cleaned_split.json
export MODEL_PATH=/path/to/Meta-Llama-3-70B-Instruct-FP8
export API_ENDPOINT=mlc # Or "sglang"/"vllm"
python3 -m mlc_llm.bench --api-endpoint $API_ENDPOINT --dataset sharegpt --dataset-path $SHAREGPT_PATH \
--tokenizer $MODEL_PATH --num-request 500 --num-gpus 4 \
--num-concurrent-requests 1,4,8,10,16,20,30,64 \
--temperature 0.6 --top-p 0.9 --ignore-eos --apply-chat-template \
--host $SERVER_ADDR --port $SERVER_PORT