UW-Madison GI Tract图像分割开源最佳方案分享
本文来自Kaggle竞赛UW-Madison GI Tract的第一名方案分享
前言
本文来自Kaggle, 主要介绍UW-Madison竞赛数据的最佳解决方案。文章末尾附有原文链接及其开源代码资料(原文链接Kaggle可以Fork运行)。
整体流程
我们2.5D解决方案的整体流程分为两个阶段:分类阶段和分割阶段。分类阶段用于判断图像中是否有目标,而分割阶段负责分割图像中的目标。通过分析分类阶段来控制目标的分割,分类和分割阶段都采用了模型权重融合,增强了我们2.5D的稳健性。纯2.5D模型在公共排行榜上得分可达0.889。具体细节如下。
数据
在数据制作方面,我们参考了@awsaf49的数据生产方法,步幅设置为2,共计三步生成2.5D数据。链接如下:https://www.kaggle.com/code/awsaf49/uwmgi-2-5d-stride-2-data。
训练与测试时增强(TTA)
我们尝试了 640*640 和 512*512 的图像分辨率。对于 640*640 的分辨率,我们在训练时采用RandomCrop方法随机裁剪448*448的目标区域。数据增强方法还包括随机翻转、弹性变换、网格扭曲和光学扭曲,具体参数如下:
dict(type='RandomFlip', direction='horizental', p=0.5)
dict(type='ElasticTransform', alpha=120, sigma=6.0, alpha_affine=3.6, p=1)
dict(type='GridDistortion', p=1)
dict(type='OpticalDistortion', distort_limit=2, shift_limit=0.5, p=1)在测试时,我们使用水平翻转生成新图像,并通过权重融合生成输出掩码。TTA可以使得我们的得分提升约0.001~0.002。
主干网络
我们的算法基于Unet模型,尝试了EfficientNet B4至B7作为主干网络,单一模型在公共排行榜上的分数约为0.883,融合多个模型后提交的分数可达0.889。深度学习框架部分参考了队友@CarnoZhao的工作:https://www.kaggle.com/code/carnozhao/uwmgit-mmsegmentation-end-to-end-submission。
训练与推理技巧 & 损失函数
分类网络在完整数据上训练,包含空图片和有掩码的图片。分割网络仅负责分割目标图像,并仅在包含掩码的图片上训练。分类网络使用单一的BCELoss,分割网络使用BCE和Dice的加权损失函数,比例为1:3。此外,使用fp16训练加速了训练速度,节省约50%的GPU内存,使我们能够使用更大的批次大小。
未来工作
在分析数据时,我发现存在一些无用的边缘信息。我尝试了CenterCrop方法去除这些无用的边缘,但对分数影响不大,效果尚不确定。
def CenterCrop(image, crop_ratio=0.9):
'''
输入numpy类型图像
crop_ratio -> 保留比例
返回裁剪图像和额外信息
'''
height, width, channel = image.shape
xmin, ymin, xmax, ymax = int(width * (1 - crop_ratio) / 2), \
int(height * (1 - crop_ratio) / 2), \
int(width * (1 + crop_ratio) / 2), \
int(height * (1 + crop_ratio) / 2)
crop_image = image[ymin:ymax, xmin:xmax, ...]
extra_info = [height, width, xmin, ymin, xmax, ymax]
return crop_image, extra_info
def PaddingCrop(crop_image, extra_info):
'''
输入crop_image -> 使用CenterCrop裁剪的图像
输入extra_info -> 原始图像大小和裁剪信息
返回填充的原始图像
'''
crop_shape = np.array(crop_image.shape[:2])
height, width, xmin, ymin, xmax, ymax = extra_info
pady = [ymin - 1, height - ymax + 1]
padx = [xmin - 1, width - xmax + 1]
original_image = np.pad(crop_image, [pady, padx, [0, 0]])
return original_image
2.5D数据生产代码
导入库
import numpy as np # 导入用于数组和矩阵操作的库
import pandas as pd # 导入用于数据处理的库
pd.options.plotting.backend = "plotly" # 设置数据绘图的后端为 Plotly
import random # 导入随机数生成器库
from glob import glob # 用于文件路径匹配
import os, shutil # 导入用于文件和文件夹操作的库
from tqdm.notebook import tqdm # 导入用于显示进度条的库
tqdm.pandas() # 为 Pandas 操作集成进度条
import time # 导入时间库,用于时间测量
import copy # 导入用于对象拷贝的库
import joblib # 导入并行计算库
import gc # 导入垃圾回收库,释放内存
from IPython import display as ipd # 用于 IPython 显示功能
from joblib import Parallel, delayed # 用于并行计算
可视化
import cv2 # 导入 OpenCV 库用于图像处理
import matplotlib.pyplot as plt # 导入 Matplotlib 用于数据可视化
from matplotlib.patches import Rectangle # 导入矩形对象,用于绘制矩形边框
import tensorflow as tf # 导入 TensorFlow 深度学习框架
参数设置
IMG_SIZE = [320, 384] # 图像尺寸设置
工具函数
# 加载图像函数,输入图像路径和大小
def load_img(path, size=IMG_SIZE):
img = cv2.imread(path, cv2.IMREAD_UNCHANGED) # 读取图像
shape0 = np.array(img.shape[:2]) # 获取图像原始尺寸
resize = np.array(size) # 目标尺寸
if np.any(shape0 != resize): # 如果需要调整图像尺寸
diff = resize - shape0 # 计算尺寸差异
pad0 = diff[0] # 计算垂直填充
pad1 = diff[1] # 计算水平填充
pady = [pad0 // 2, pad0 // 2 + pad0 % 2] # 计算垂直填充边界
padx = [pad1 // 2, pad1 // 2 + pad1 % 2] # 计算水平填充边界
img = np.pad(img, [pady, padx]) # 填充图像
img = img.reshape((*resize)) # 调整图像形状
return img
加载掩码函数
# 加载掩码函数,输入路径和图像尺寸
def load_msk(path, size=IMG_SIZE):
msk = np.load(path) # 载入掩码
shape0 = np.array(msk.shape[:2]) # 获取掩码原始尺寸
resize = np.array(size) # 目标尺寸
if np.any(shape0 != resize): # 如果需要调整掩码尺寸
diff = resize - shape0 # 计算尺寸差异
pad0 = diff[0] # 计算垂直填充
pad1 = diff[1] # 计算水平填充
pady = [pad0 // 2, pad0 // 2 + pad0 % 2] # 计算垂直填充边界
padx = [pad1 // 2, pad1 // 2 + pad1 % 2] # 计算水平填充边界
msk = np.pad(msk, [pady, padx, [0, 0]]) # 填充掩码
msk = msk.reshape((*resize, 3)) # 调整掩码形状
return msk
可视化图像和掩码
# 显示图像和掩码
def show_img(img, mask=None):
plt.imshow(img, cmap='bone') # 显示原图像
if mask is not None: # 如果存在掩码
plt.imshow(mask, alpha=0.5) # 将掩码覆盖在图像上
handles = [Rectangle((0, 0), 1, 1, color=_c) for _c in [(0.667, 0.0, 0.0), (0.0, 0.667, 0.0), (0.0, 0.0, 0.667)]]
labels = ["Large Bowel", "Small Bowel", "Stomach"]
plt.legend(handles, labels) # 显示图例
plt.axis('off') # 隐藏坐标轴
加载图像列表
# 加载多个图像
def load_imgs(img_paths, size=IMG_SIZE):
imgs = np.zeros((*size, len(img_paths)), dtype=np.uint16) # 初始化空数组
for i, img_path in enumerate(img_paths):
img = load_img(img_path, size=size) # 加载图像
imgs[..., i] += img # 存入数组
return imgs
元数据处理
df = pd.read_csv('../input/uwmgi-mask-dataset/train.csv') # 加载CSV文件
df['segmentation'] = df.segmentation.fillna('') # 用空字符串填充缺失数据
df['rle_len'] = df.segmentation.map(len) # 计算每个掩码的长度
df['mask_path'] = df.mask_path.str.replace('/png/', '/np').str.replace('.png', '.npy')
# 分组并计算聚合数据
df2 = df.groupby(['id'])['segmentation'].agg(list).to_frame().reset_index()
df2 = df2.merge(df.groupby(['id'])['rle_len'].agg(sum).to_frame().reset_index())
df = df.drop(columns=['segmentation', 'class', 'rle_len'])
df = df.groupby(['id']).head(1).reset_index(drop=True)
df = df.merge(df2, on=['id'])
df['empty'] = (df.rle_len == 0) # 判断掩码是否为空
df.head()
生成2.5D图像
channels = 3
stride = 2
for i in range(channels):
df[f'image_path_{i:02}'] = df.groupby(['case', 'day'])['image_path'].shift(-i * stride).fillna(method="ffill")
df['image_paths'] = df[[f'image_path_{i:02d}' for i in range(channels)]].values.tolist()
检查掩码
# 随机选择带掩码的数据并显示
row = 1
col = 4
plt.figure(figsize=(5 * col, 5 * row))
for i, id_ in enumerate(df[df['empty'] == 0].sample(frac=1.0)['id'].unique()[:row * col]):
idf = df[df['id'] == id_]
img = load_img(idf.image_path.iloc[0])
mask = load_msk(idf.mask_path.iloc[0])
plt.subplot(row, col, i + 1)
show_img(img, mask=mask)
plt.tight_layout()
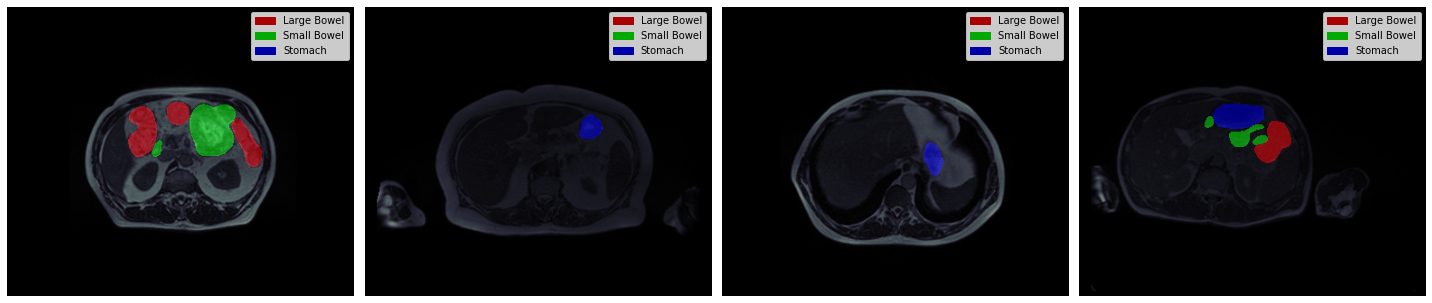
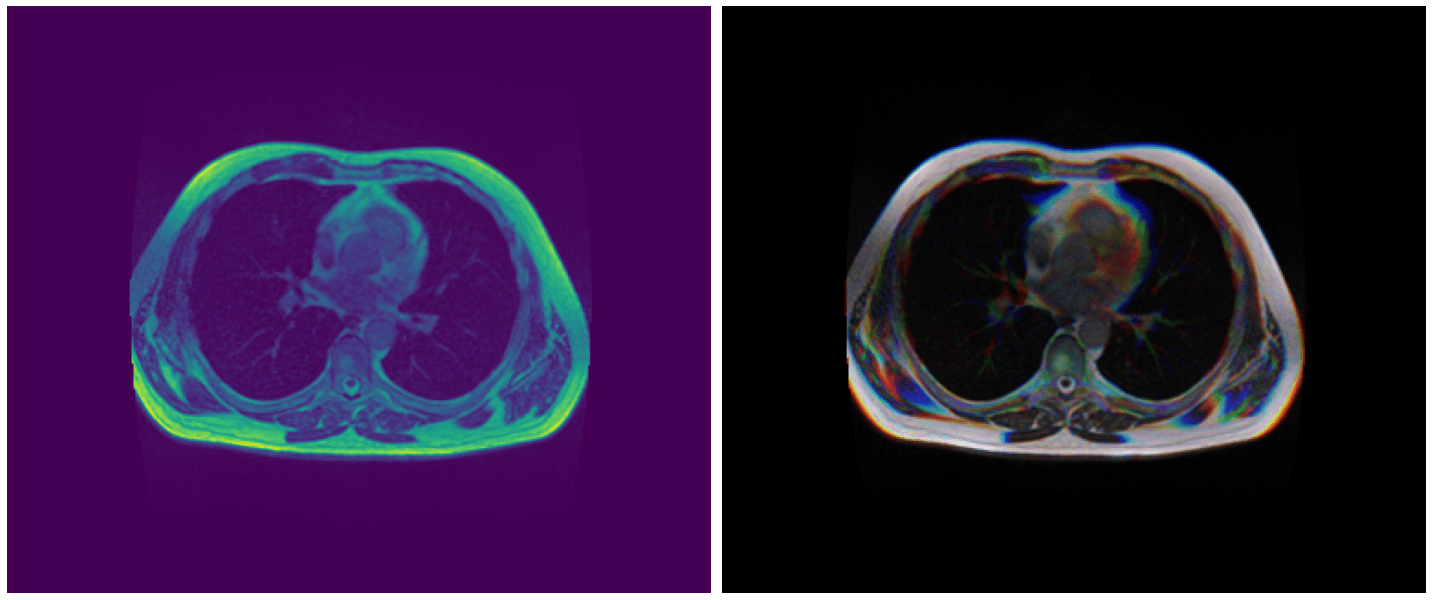
检查2.5D数据
idx = 40
plt.figure(figsize=(20, 10))
plt.subplot(1, 2, 1)
img = load_img(df.image_path[idx]).astype('float32')
img /= img.max()
plt.imshow(img)
plt.axis('off')
plt.subplot(1, 2, 2)
imgs = load_imgs(df.image_paths[idx]).astype('float32')
imgs /= imgs.max(axis=(0, 1))
plt.imshow(imgs)
plt.axis('off')
plt.tight_layout()
plt.show()
保存掩码和图像
# 保存图像和掩码
def save_mask(id_):
row = df[df['id'] == id_].squeeze()
img_paths = row.image_paths
imgs = load_imgs(img_paths)
np.save(f'{IMAGE_DIR}/{id_}.npy', imgs)
msk_path = row.mask_path
msk = load_msk(msk_path)
np.save(f'{MASK_DIR}/{id_}.npy', msk)
IMAGE_DIR = '/tmp/images'
MASK_DIR = '/tmp/masks'
!mkdir -p $IMAGE_DIR && mkdir -p $MASK_DIR
ids = df['id'].unique()
_ = Parallel(n_jobs=-1, backend='threading')(delayed(save_mask)(id_)\
for id_ in tqdm(ids, total=len(ids)))检查掩码
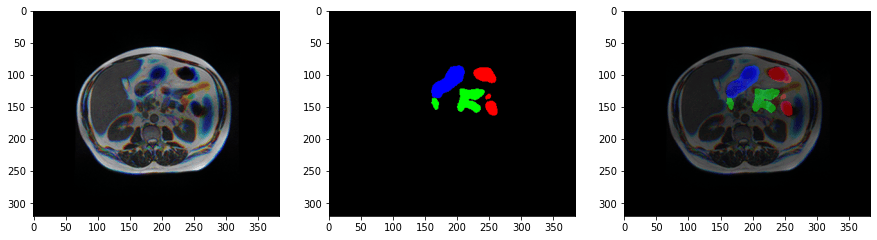
plt.figure(figsize=(15, 5))
imgs = np.load(f'{IMAGE_DIR}/case123_day0_slice_0080.npy').astype('float32')
imgs/=imgs.max(axis=(0,1))
plt.subplot(1, 3, 1)
plt.imshow(imgs)
msk = np.load(f'{MASK_DIR}/case123_day0_slice_0080.npy').astype('float32')
msk/=255.0
plt.subplot(1, 3, 2)
plt.imshow(msk)
plt.subplot(1, 3, 3)
plt.imshow(imgs)
plt.imshow(msk, alpha=0.5)