蒙特卡洛树搜索 (MCTS) 算法通俗指南
一套MCTS的解说及代码实现,用AI玩游戏吧!
前言
本文属于搬运内容,原作者:michelangelo (Salute!)
如果我们想真正理解 AlphaZero 和 MuZero 的工作原理,就必须先深入了解蒙特卡洛树搜索 (Monte Carlo Tree Search, MCTS) 算法,它是这两个算法的基础。
粗略理解
MCTS 让我们能够通过统计方法而非完全探索来寻找最佳的行动路径,从而可以在较少限制的情况下导航庞大的状态空间,而不像蛮力搜索那样效率低下。
事实上,MCTS 的搜索过程是有指导的:它会更频繁地探索有希望的节点,收集的统计数据越多,得到的结果就越可靠。
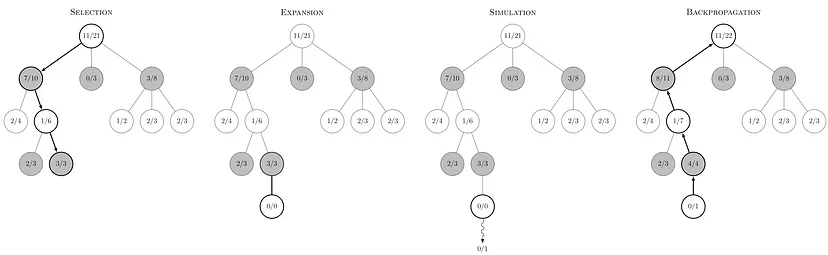
更具体地说,MCTS 包括以下四个步骤:
- 选择 (Selection)我们需要一种聪明的方法来探索树中的节点,以便找到更有前景的结果。因此,需要对节点赋予某种价值,以便选择要探索的节点。
- 扩展 (Expansion)当到达一个叶子节点(即游戏的某一状态)时,需要扩展树,考虑从该节点出发的所有可能的有效行动(即采取有效行动后游戏的后续状态)。
- 模拟 (Simulation)从某个节点(游戏状态)开始,我们需要能够模拟一场完全随机的游戏。单独的一次模拟可能会得到随机的结果,但随着从该节点进行的模拟次数增加,节点的平均价值估计会变得越来越准确。
- 回溯 (Backpropagation)模拟完成后,需要将结果向上传播到树的上层节点,以便在上层节点中存储这些信息,从而将叶子节点的信息传递到根节点。
具体实施
简而言之,MCTS 算法的四个步骤重复执行得越多,我们关于从特定游戏状态采取最佳行动的信息就越可靠、统计上越有效。将这些步骤应用于每一次行动,我们就可以像高手一样制定游戏策略!
接下来,我们看看如何实现 MCTS 并将其用于玩一个 OpenAI Gym 的视频游戏。
创建环境
1. 创建 OpenAI Gym 环境
首先,我们需要创建一个 OpenAI Gym 环境作为算法的测试平台,并检查游戏中可能的动作数量以及观察空间的维度。以下是代码实现:
import gym
# 游戏名称
GAME_NAME = 'CartPole-v0'
# 创建环境
env = gym.make(GAME_NAME)
# 获取游戏的可能动作数和观察空间维度
GAME_ACTIONS = env.action_space.n
GAME_OBS = env.observation_space.shape[0]
# 输出游戏信息
print('In the ' + GAME_NAME + ' environment there are: ' + str(GAME_ACTIONS) + ' possible actions.')
print('In the ' + GAME_NAME + ' environment the observation is composed of: ' + str(GAME_OBS) + ' values.')
# 重置环境
env.reset()
# 关闭环境
env.close()
代码解释:
gym.make(GAME_NAME):加载指定游戏环境(这里是 CartPole-v0)。
env.action_space.n:返回游戏中可能的动作数量(离散动作空间)。
env.observation_space.shape[0]:返回观察空间的维度,即环境提供的观测值数量。
env.reset():重置环境以准备新一轮模拟。
env.close():关闭环境释放资源。
执行这段代码,你会看到类似以下的输出:
In the CartPole-v0 environment there are: 2 possible actions.
In the CartPole-v0 environment the observation is composed of: 4 values.
这表明 CartPole-v0 游戏有两个可能的动作(向左或向右),观察值由 4 个变量组成(如位置、速度、角度等)。
接下来,你可以基于这个环境实现 MCTS 算法,模拟和评估不同的动作选择策略。
CartPole 环境和 MCTS 树的 Node 类定义
1. CartPole 环境简介
在 CartPole 环境中,目标是通过向左右施加力使小车保持平衡,从而避免连接的杆子倒下:
- 可能的动作:向左推小车或向右推小车(2 种可能动作)。
- 观察值:由 4 个值组成:
2. Node 类定义Node 类用于表示 MCTS 树中的一个节点,包含了算法运行所需的信息:
class Node:
'''
Node 类表示 MCTS 树中的一个节点。
它包含算法执行搜索所需的全部信息。
'''
def __init__(self, game, done, parent, observation, action_index):
# 子节点字典 {action: child_node}
self.child = {}
# 来自 MCTS 探索的总奖励值
self.T = 0
# 节点访问次数
self.N = 0
# 环境副本,表示当前节点的游戏状态
self.game = game
# 环境的当前观测值
self.observation = observation
# 游戏是否结束(胜/负/平)
self.done = done
# 指向父节点的链接(用于回溯)
self.parent = parent
# 导致到达当前节点的动作索引
self.action_index = action_index
Node 类的关键属性详解
- child子节点字典,表示当前节点采取不同动作后的后续状态。结构:{action_index: child_node}。
- T从该节点开始的模拟(rollouts)的总奖励值。用于统计从该节点起步的探索质量。
- N节点访问次数,表示从根节点到达该节点的次数。用于平衡探索(未被充分访问的节点)和利用(高奖励节点)。
- game游戏环境的当前状态。是原始环境的副本,用于模拟和搜索。
- observation节点表示的游戏状态,在 CartPole 中即 4 个观察值。
- done表示游戏是否在当前节点结束(例如杆子倒下、小车越界等)。如果结束,则停止进一步扩展和模拟。
- parent父节点的引用,用于回溯(backpropagation)。
- action_index父节点采取的动作索引,用于从父节点到达当前节点。
定义 Node 中的赋值以支持搜索
我们首先定义一个方法,用于为节点赋值。这是非常关键的步骤,因为它将指导我们沿着搜索树进行探索:
def getUCBscore(self):
'''
该公式为节点赋值。
MCTS 将选择值最大的节点进行进一步搜索。
'''
# 未探索的节点分配最大值以鼓励探索
if self.N == 0:
return float('inf')
# 获取当前节点的父节点
top_node = self
if top_node.parent:
top_node = top_node.parent
# 使用 MCTS 的公式之一计算节点的值
return (self.T / self.N) + c * sqrt(log(top_node.N) / self.N)
公式解释:UCB(Upper Confidence Bound)

方法运行逻辑

定义函数创建子节点
def create_child(self):
'''
我们为游戏中的每个可能动作创建一个子节点,
然后将该动作应用于当前节点环境的一个副本,
并使用执行该动作后返回的相关信息创建对应的子节点。
'''
if self.done:
return
actions = []
games = []
for i in range(GAME_ACTIONS):
actions.append(i)
new_game = deepcopy(self.game)
games.append(new_game)
child = {}
for action, game in zip(actions, games):
observation, reward, done, _ = game.step(action)
child[action] = Node(game, done, self, observation, action)
self.child = child
注意,我们始终使用游戏中所有可能的动作(GAME_ACTIONS),为每个动作创建一个子节点,并将游戏环境的副本与该动作关联。在此基础上,通过执行动作(game.step(action))获取游戏的结果状态信息,并将其存储到子节点中。
定义搜索
我们现在准备实现算法的核心部分,在这里进行搜索:
def explore(self):
'''
树的搜索过程如下:
- 从当前节点开始,递归地选择最大化 MCTS 公式值的子节点
- 当到达叶节点时:
- 如果该节点之前从未被探索过,则执行一次随机游戏并更新其当前值
- 否则,扩展该节点,创建其子节点,随机选择一个子节点,执行随机游戏并更新其值
- 将更新后的统计信息从叶节点回传到树的根节点:更新值和访问次数
'''
# 通过选择具有最大 U 值的节点来寻找叶节点
current = self
while current.child:
child = current.child
max_U = max(c.getUCBscore() for c in child.values())
actions = [a for a, c in child.items() if c.getUCBscore() == max_U]
if len(actions) == 0:
print("error zero length ", max_U)
action = random.choice(actions)
current = child[action]
# 执行随机游戏,或者如果需要,扩展节点
if current.N < 1:
current.T = current.T + current.rollout()
else:
current.create_child()
if current.child:
current = random.choice(current.child)
current.T = current.T + current.rollout()
current.N += 1
# 更新统计信息并回传
parent = current
while parent.parent:
parent = parent.parent
parent.N += 1
parent.T = parent.T + current.T
树的搜索过程
- 递归选择子节点:
- 从当前节点开始,递归地选择最大化 UCB 值的子节点,直到达到一个叶节点。
- 叶节点的处理:
- 如果是第一次访问该叶节点,就进行一次随机游戏(rollout),并更新其值。
- 如果该节点已经被访问过,扩展该节点,创建子节点,然后随机选择一个子节点进行随机游戏并更新其值。
- 回传更新的统计信息:
- 无论哪种情况,都会将更新的统计信息(包括值和访问次数)回传到父节点,直到根节点。
算法工作流程总结
- 选择最大 UCB 值的子节点
- 递归地进行搜索直到找到叶节点。
- 叶节点处理:
- 如果叶节点没有被访问过,则进行一次随机模拟并更新值。
- 如果叶节点已被访问,则扩展节点并选择一个随机子节点进行模拟。
- 回传统计信息:
- 更新每个节点的统计信息并回传,直到树的根节点。
定义随机回合
我们差不多完成了,接下来我们需要定义如何进行随机回合(rollout),使用当前节点的游戏副本(即当前游戏状态):
def rollout(self):
'''
回合是从当前节点的环境副本开始,使用随机动作进行的游戏模拟。
这将为当前节点提供一个值。
单独来看,这个值是随机的,但是,进行更多的回合后,
该节点的平均值将会更加准确。这是 MCTS 算法的核心。
'''
if self.done:
return 0
v = 0
done = False
new_game = deepcopy(self.game)
while not done:
action = new_game.action_space.sample() # 随机选择一个动作
observation, reward, done, _ = new_game.step(action)
v = v + reward # 累加奖励
if done:
new_game.reset() # 游戏结束时重置游戏
new_game.close()
break
return v
回合过程:
- 随机播放:从当前节点的游戏副本开始,随机选择动作进行游戏直到结束。
- 回合值:游戏的累计奖励值
v作为当前节点的估计值。进行更多回合会使得值更准确。
然后,我们需要定义如何在搜索完成后选择下一个动作:
def next(self):
'''
一旦在树中进行了足够的搜索,树中包含的值应该是统计上准确的。
然后,我们将选择从当前节点开始的下一个动作,这就是这个函数的作用。
选择动作的方法有多种,这个实现的策略如下:
- 从具有最大访问次数的节点中随机选择一个,因为这意味着该节点有一个好的值。
'''
if self.done:
raise ValueError("game has ended")
if not self.child:
raise ValueError('no children found and game hasn\'t ended')
child = self.child
# 找到最大访问次数的节点
max_N = max(node.N for node in child.values())
# 找到所有访问次数为最大值的子节点
max_children = [c for a, c in child.items() if c.N == max_N]
if len(max_children) == 0:
print("error zero length ", max_N)
max_child = random.choice(max_children)
return max_child, max_child.action_index
选择下一个动作的过程:
- 根据访问次数选择子节点:从当前节点的子节点中选择访问次数最多的子节点,这通常意味着该节点具有较好的值(因为 MCTS 公式会优先选择访问次数多的节点)。
- 随机选择:如果多个子节点具有相同的最大访问次数,则随机选择其中一个。
通过这种方式,我们能够确保搜索过的节点更加准确,并最终选择最合适的动作。
开始玩游戏!
现在我们已经准备好了,接下来我们需要定义用于玩游戏的策略:
MCTS_POLICY_EXPLORE = 100 # MCTS探索常数:值越高,越可靠,但执行时间更长
def Policy_Player_MCTS(mytree):
'''
我们使用 MCTS 的策略非常简单:
- 为了从当前节点选择最佳动作:
- 从该节点开始探索树,进行一定数量的迭代,以收集可靠的统计信息
- 根据 MCTS,选择下一个最佳的动作节点
'''
for i in range(MCTS_POLICY_EXPLORE):
mytree.explore()
next_tree, next_action = mytree.next()
# 注意这里我们将当前节点与其子树分离,并返回从选定动作开始的新树。
# 下一次搜索将不会从头开始,而是已经收集了节点的信息和统计数据,
# 所以我们可以重用这些统计数据,使得搜索结果更加可靠!
next_tree.detach_parent()
return next_tree, next_action
策略说明:
- 探索树并选择最佳动作:每次需要做出游戏动作时,使用 MCTS 进行探索,并选择最佳可能的下一步动作。探索树的次数由固定参数
MCTS_POLICY_EXPLORE控制,探索次数越多,结果越可靠。
- 重用统计信息:每次选择动作后,都会通过
detach_parent()将当前节点与其父节点分离,从而确保下一次搜索可以重用已有的统计信息。
接下来是运行我们的策略并查看效果的代码:
episodes = 10
rewards = []
moving_average = []
'''
在这里我们测试我们的实现:
- 玩一定数量的游戏回合
- 每次做出动作时,都会应用我们的 MCTS 算法
- 收集并绘制奖励,检查 MCTS 是否有效。
- 对于 CartPole-v0,最大可能奖励为 200。
'''
for e in range(episodes):
reward_e = 0
game = gym.make(GAME_NAME)
observation = game.reset()
done = False
new_game = deepcopy(game)
mytree = Node(new_game, False, 0, observation, 0)
print('episode #' + str(e+1))
while not done:
mytree, action = Policy_Player_MCTS(mytree)
observation, reward, done, _ = game.step(action)
reward_e = reward_e + reward
# game.render() # 如果你想看到智能体的动作,取消注释此行!
if done:
print('reward_e ' + str(reward_e))
game.close()
break
rewards.append(reward_e)
moving_average.append(np.mean(rewards[-100:]))
plt.plot(rewards)
plt.plot(moving_average)
plt.show()
print('moving average: ' + str(np.mean(rewards[-20:])))
运行流程:
- 游戏回合数:我们设置了
episodes = 10,即进行 10 次游戏。
- 奖励收集:在每次游戏结束后,收集奖励并将其存储在
rewards列表中。同时,我们计算并绘制每 100 次回合的移动平均奖励,以检查 MCTS 算法是否有效。
- 显示结果:最终绘制奖励和移动平均的曲线图,查看随着时间推移奖励的变化情况。
对于 CartPole-v0 环境,最大奖励为 200,若 MCTS 算法有效,我们应该看到随着回合数的增加,奖励逐渐接近这一最大值。
结语
恭喜你!你做到了! 干就完了! 希望你在这其中找到了乐趣~