数据分析2.4 —— 学会贝叶斯优化,调参无忧!
你还在为了参数组合而烦恼吗?还在傻傻遍历搜寻吗?
贝叶斯优化简介
贝叶斯优化(Bayesian Optimization)是一种用于黑盒函数优化的方法,特别适合那些无法通过解析手段进行优化、且每次评估代价较高的函数。在机器学习中,贝叶斯优化常用于超参数调优,因为训练模型的过程本身可能非常耗时,而我们希望通过尽量少的训练次数找到最优的超参数组合。
贝叶斯优化的核心思想是构建一个代理模型(通常是高斯过程),根据当前已经评估过的点来预测函数的分布,并根据这个分布选择下一个值得评估的点。与传统的网格搜索或随机搜索不同,贝叶斯优化在每一步都会根据先前的结果来“智能地”选择下一个测试的超参数组合,从而更高效地找到全局最优解。
其数学过程可以概括为黑盒函数优化问题,即我们不知道目标函数的明确表达式,但可以通过有限的观测来估计最优解。贝叶斯优化通过构建一个代理模型来逼近目标函数,并使用采集函数来决定下一个值得探索的点。具体过程如下:
1. 目标函数
设目标函数为 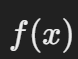 ,其中 x 是超参数的集合。我们希望找到使得
,其中 x 是超参数的集合。我们希望找到使得 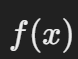 最大化或最小化的 x,例如优化机器学习模型的交叉验证得分。
最大化或最小化的 x,例如优化机器学习模型的交叉验证得分。
2. 代理模型(高斯过程)

3. 采集函数
贝叶斯优化通过一个采集函数来选择下一个超参数组合,该采集函数会基于代理模型当前对目标函数的估计值和不确定性来决定。在常见的采集函数中,**预期改进(Expected Improvement, EI)**函数是一个广泛使用的采集函数,其表达式为:

贝叶斯优化基本步骤
贝叶斯优化的基本步骤如下:
- 定义代理模型:贝叶斯优化首先为目标函数(如模型的交叉验证得分)构建一个代理模型。最常用的代理模型是高斯过程(Gaussian Process),它为目标函数的每个输入点预测输出的均值和方差。
- 最大化采集函数:贝叶斯优化使用采集函数(Acquisition Function)来决定下一个需要评估的超参数组合。采集函数平衡了探索和利用之间的权衡:探索:评估当前模型不确定性较大的区域,可能找到更好的超参数。利用:选择当前已知的最优区域,进一步优化。
- 更新代理模型:根据新评估的超参数组合更新代理模型,并重复这个过程,直到达到终止条件(如最大评估次数或时间限制)。
贝叶斯优化应用于机器学习调参
在机器学习中,贝叶斯优化常用于超参数调优,例如选择决策树的深度、学习率等。它能在较少的迭代次数中找到比随机搜索或网格搜索更好的超参数。
代码演示:使用贝叶斯优化进行超参数调优(Titanic数据集)
我们将使用scikit-optimize中的BayesSearchCV来进行贝叶斯优化。
1. 安装scikit-optimize
首先确保你安装了scikit-optimize库。如果未安装,可以通过以下命令安装:
pip install scikit-optimize
2. 导入必要的库
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from skopt import BayesSearchCV
from skopt.space import Integer, Real
3. 加载和预处理数据
我们使用Titanic数据集,并对其进行基本的预处理。
# 加载数据集
df = pd.read_csv('titanic.csv')
# 简单数据预处理:填充缺失值并进行编码
df['Age'].fillna(df['Age'].median(), inplace=True)
df['Embarked'].fillna('S', inplace=True)
df = pd.get_dummies(df, columns=['Sex', 'Embarked'], drop_first=True)
# 特征和标签
X = df.drop(columns=['Survived', 'PassengerId', 'Name', 'Ticket', 'Cabin'])
y = df['Survived']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
4. 定义随机森林模型及其超参数空间
我们将对RandomForestClassifier的几个关键超参数进行优化,包括树的数量(n_estimators)、最大深度(max_depth)和最小样本叶子节点数(min_samples_leaf)。
# 定义超参数搜索空间
search_space = {
'n_estimators': Integer(50, 500), # 决策树数量
'max_depth': Integer(3, 15), # 树的最大深度
'min_samples_split': Integer(2, 20), # 内部节点再划分所需最小样本数
'min_samples_leaf': Integer(1, 10), # 叶子节点最小样本数
'max_features': Real(0.1, 1.0, prior='uniform') # 每次分裂时使用的特征数比例
}
# 定义随机森林模型
rf_model = RandomForestClassifier(random_state=42)
5. 使用贝叶斯优化调参
我们使用BayesSearchCV,它类似于GridSearchCV,但使用贝叶斯优化来选择超参数。
# 使用贝叶斯优化进行超参数调优
opt = BayesSearchCV(
rf_model,
search_spaces=search_space,
n_iter=32, # 优化迭代次数
cv=3, # 交叉验证次数
random_state=42
)
# 训练模型并搜索最佳超参数
opt.fit(X_train, y_train)
# 打印最佳超参数组合
print("最优超参数组合:", opt.best_params_)
6. 评估模型性能
使用贝叶斯优化找到的最优超参数组合,在测试集上进行预测,并计算准确率。
# 使用最佳模型在测试集上进行预测
y_pred = opt.predict(X_test)
# 输出模型的准确率
print("贝叶斯优化后模型的准确率:", accuracy_score(y_test, y_pred))
其他可选库Optuna
使用Optuna进行贝叶斯优化超参数调优
Optuna 是一个高效的超参数调优框架,使用贝叶斯优化策略来加速搜索。它的简单性和灵活性使其非常适合处理复杂的调参任务。
1. 安装Optuna
pip install optuna
2. 导入必要的库
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import accuracy_score
import optuna
3. 加载和预处理Titanic数据集
# 加载数据集
df = pd.read_csv('titanic.csv')
# 数据预处理
df['Age'].fillna(df['Age'].median(), inplace=True)
df['Embarked'].fillna('S', inplace=True)
df = pd.get_dummies(df, columns=['Sex', 'Embarked'], drop_first=True)
X = df.drop(columns=['Survived', 'PassengerId', 'Name', 'Ticket', 'Cabin'])
y = df['Survived']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
4. 定义优化目标函数
在Optuna中,我们需要定义一个优化目标函数,它返回我们希望最小化的或最大化的目标(比如误差或准确率的负值)。在这个例子中,我们对RandomForestClassifier进行超参数调优,并最大化交叉验证的准确率。
def objective(trial):
# 定义随机森林的超参数搜索空间
n_estimators = trial.suggest_int('n_estimators', 50, 500)
max_depth = trial.suggest_int('max_depth', 3, 15)
min_samples_split = trial.suggest_int('min_samples_split', 2, 20)
min_samples_leaf = trial.suggest_int('min_samples_leaf', 1, 10)
max_features = trial.suggest_uniform('max_features', 0.1, 1.0)
# 使用超参数创建随机森林模型
rf_model = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf,
max_features=max_features,
random_state=42
)
# 使用交叉验证评估模型的准确率
score = cross_val_score(rf_model, X_train, y_train, cv=3, scoring='accuracy').mean()
return score # 我们希望最大化准确率
5. 运行贝叶斯优化
现在我们可以使用Optuna的study来运行贝叶斯优化,并设定运行的迭代次数。
# 创建Optuna的study对象
study = optuna.create_study(direction='maximize') # 我们希望最大化准确率
study.optimize(objective, n_trials=50) # 运行50次迭代
# 打印最佳超参数组合
print("最佳超参数组合:", study.best_params)
6. 评估模型性能
使用Optuna找到的最优超参数组合训练随机森林模型,并在测试集上进行预测,计算模型的准确率。
# 使用最佳超参数组合重新训练模型
best_rf_model = RandomForestClassifier(
n_estimators=study.best_params['n_estimators'],
max_depth=study.best_params['max_depth'],
min_samples_split=study.best_params['min_samples_split'],
min_samples_leaf=study.best_params['min_samples_leaf'],
max_features=study.best_params['max_features'],
random_state=42
)
best_rf_model.fit(X_train, y_train)
y_pred = best_rf_model.predict(X_test)
# 输出模型的准确率
print("贝叶斯优化后模型的准确率:", accuracy_score(y_test, y_pred))总结
- 贝叶斯优化的优势:与传统的网格搜索和随机搜索相比,贝叶斯优化能够在较少的超参数组合评估次数中找到更优的参数组合,尤其适用于高代价的模型训练和评估任务。
- 贝叶斯优化的局限性:虽然贝叶斯优化在高效调优方面表现出色,但它仍然需要一定的初始评估数据来构建代理模型。对于非常高维的搜索空间,贝叶斯优化的表现可能受限于采集函数的选择和代理模型的准确性。
通过贝叶斯优化,我们能够有效地减少调参的时间和计算资源,并提升模型的性能。