使用统计分析进行时间序列异常检测
从头到尾的异常检测系统构建!!!!!!!
前言
本文属于搬运内容,原作者:Ivan Shubin,原文链接。
为指标设置告警并不总是那么简单。在某些情况下,一个简单的阈值就足够了——比如监控设备上的磁盘空间。你可以直接设置一个剩余10%的警报,就能有效覆盖。同样,监控服务器的可用内存时也可以这么做。
但如果我们需要监控诸如网站上的用户行为呢?
想象一下你在运营一个在线商店销售产品。一个办法是为每日销售额设定一个最低阈值,每天检查一次。但如果出现了问题,而你需要更早发现,比如在几小时甚至几分钟内发现呢?在这种情况下,静态阈值就不够用了,因为用户活动在一天中是波动的。这时就需要用到异常检测了。
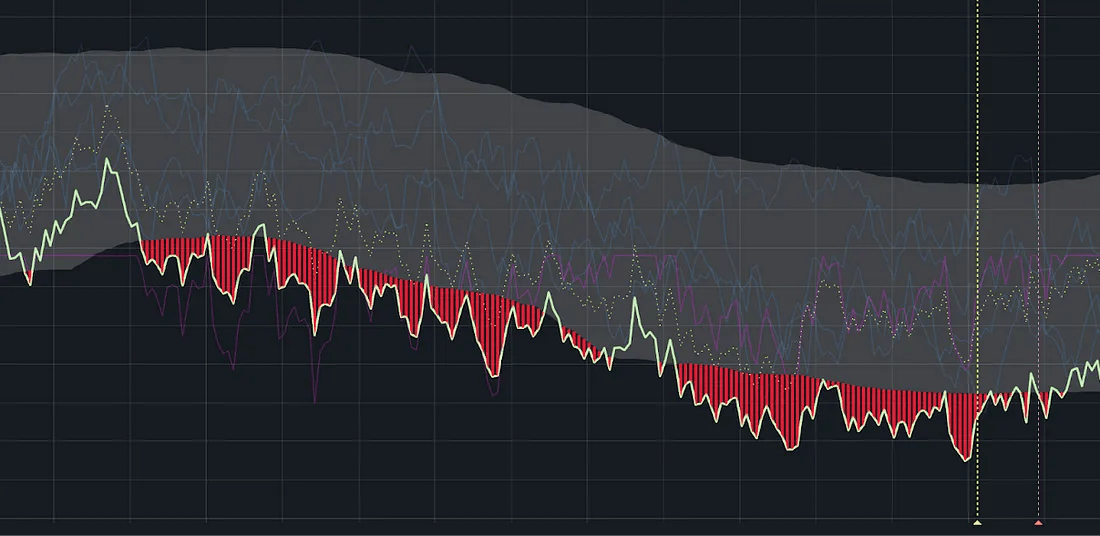
什么是异常检测?
与依赖简单规则不同,异常检测涉及分析历史数据,以发现不寻常的模式。实现异常检测的方法有很多种,包括机器学习和统计分析。本文将聚焦在统计方法,并讲述我们如何在Booking公司从零构建了自己的时间序列异常检测系统。
朴素的方法(Naïve Approach)
我在不同的公司和团队中常见的一个错误是:简单地将业务指标与一周前的数值进行比较,以此来检测异常。
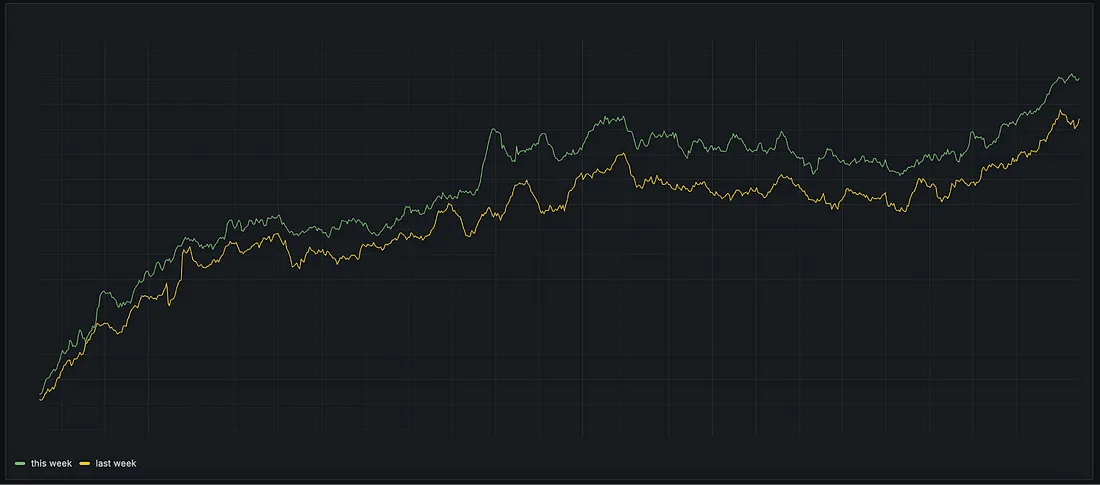
本周 vs 上周
乍一看,这种方法并非一无是处——如上图所示,有时确实能捕捉到一些异常。但它能作为一个可靠的长期解决方案吗?并不能。
它最大的缺陷在于:今天的异常会成为下周的基准线。这意味着如果同样的问题在下周同一时间再次发生,它可能完全不会被检测到,因为此时我们是在和一个已经被破坏的参考点作比较。
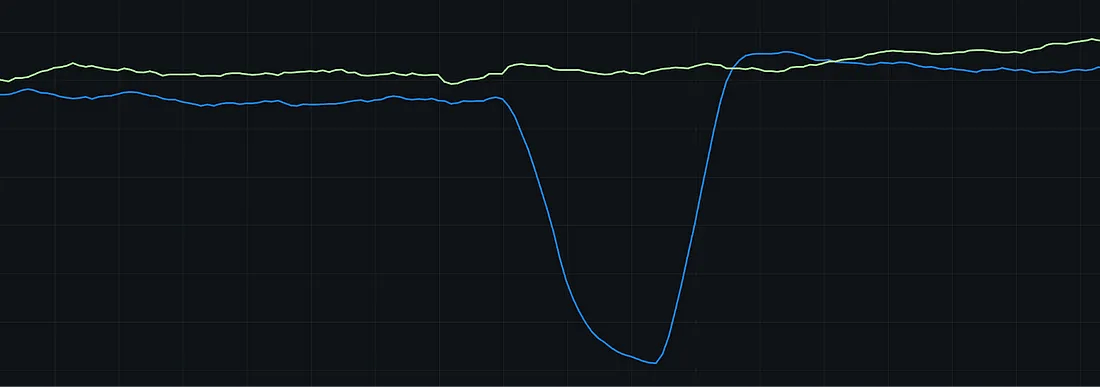
上周的故障
这样看起来显然有问题。
我们这种过于简化的方法并不知道上周的数据已经被破坏了。
此外,这种方法的另一个局限是它只考虑单一周的数据。但如果性能是在几周内逐渐下降呢?
这种慢性问题,很可能就会在这种比较方式下被完全忽略。
统计学(Statistics)
在这一点上,我开始问自己:从零构建一个异常检测系统到底有多难?
我知道有很多基于机器学习的解决方案,但一个简单的统计方法能否胜任?更重要的是——效果会不会足够好?
让我们深入了解一下。
首先,我们来看一下最基础的统计量之一:标准差(Standard Deviation)。
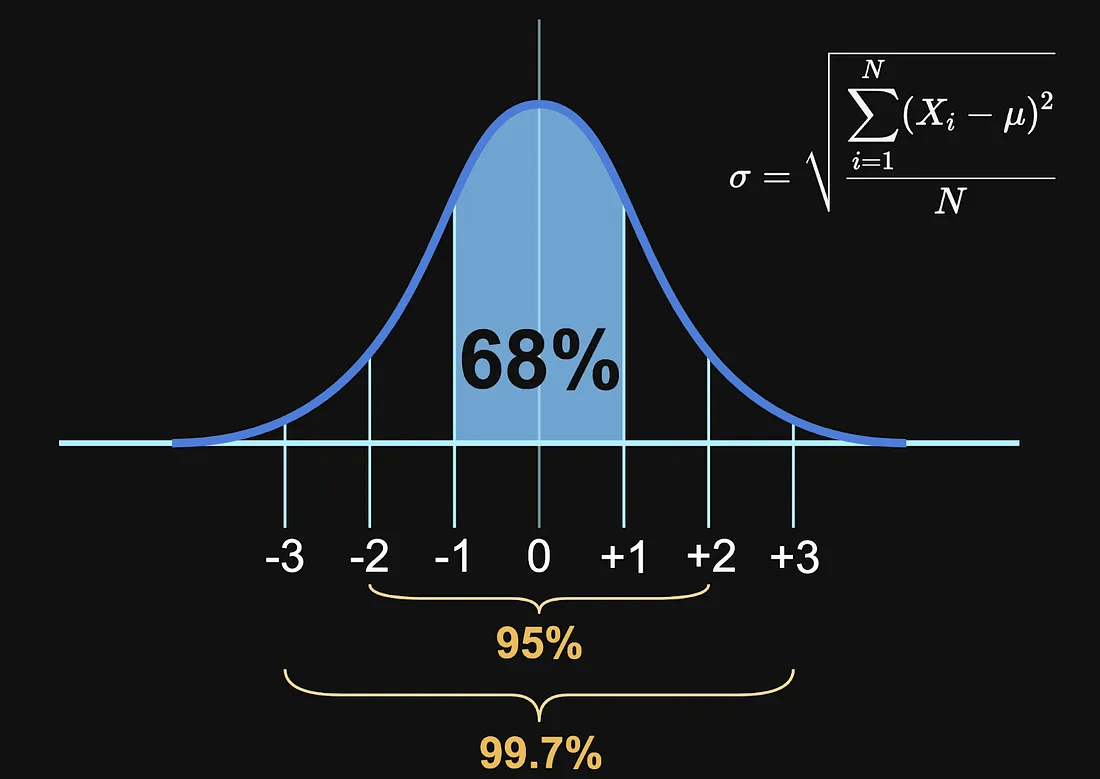
标准差
你可能已经见过这个钟形曲线(正态分布)了,但标准差到底能怎么帮助我们呢?
关键思想是:用标准差来衡量时间序列数据中的波动情况。
举个例子:
如果我们放大观察一个很小的时间窗口,比如最近20分钟的数据,并将它与过去四周在同一时间段的数据进行比较,我们可能会看到这样的情况:
本周(绿色) vs 多周历史(蓝色)
如你所见,这些指标存在很大的波动性。
我们可以通过计算给定时间段内的标准差,来量化这种波动。
为了让它更直观,我们可以绘制一张图,将数据的**均值(mean)以及上下一个标准差(±1σ)**的范围一起画出来:
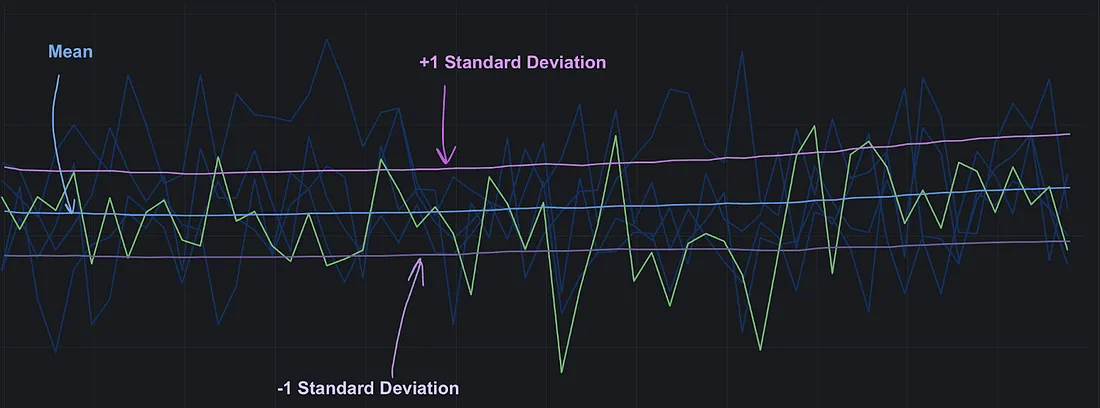
随时间变化的标准差
如果我们进一步放大时间尺度,计算更长时间段内的标准差,还可以观察到更广泛的波动趋势:
随时间变化的标准差(放大版)
当我们掌握了均值和标准差这两个量后,就可以构建出一个非常强大的统计工具:z-score(标准分数),
它可以用来识别异常值(outliers),从而检测出数据中的异常情况。
什么是 Z 分数(Z-Score)?
引用自维基百科:
在统计学中,标准分数(standard score)或 Z 分数(z-score)是指一个原始分数(即观察到的值或数据点)与被观察或测量对象的均值相比,偏离多少个标准差。 原始分数高于均值时,Z 分数为正;低于均值时,Z 分数为负。
计算 Z 分数的公式如下:
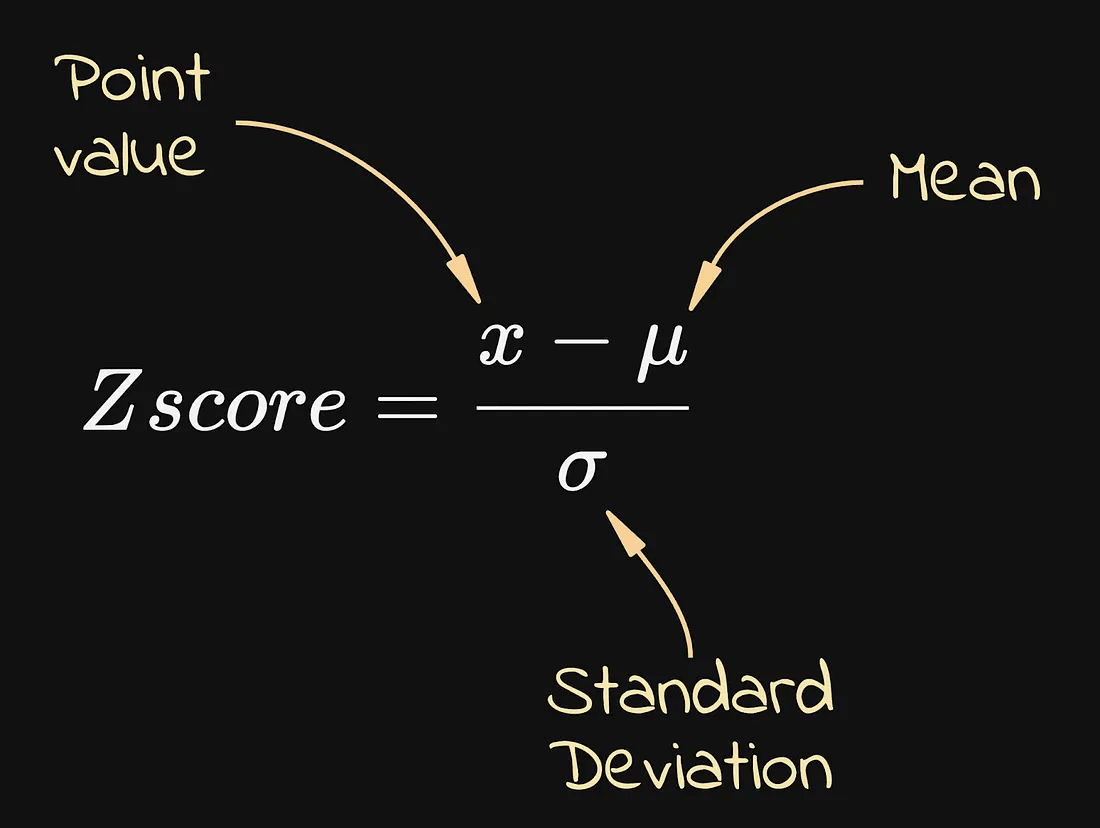
简单来说,Z 分数衡量的是某个数据点距离均值有多远。
而这对我们来说非常有用!实际上,它提供了一种**直接检测时间序列数据中异常值(outliers)**的方法。
这也是我们在异常检测中采取的第一个方法,下面是具体做法:
想象一下,我们要为以下这个指标建立异常检测系统:
本周数据
乍一看,很难判断图中后期出现的下降是正常现象还是异常。
但如果我们把之前几周的数据也画在同一张图上呢?
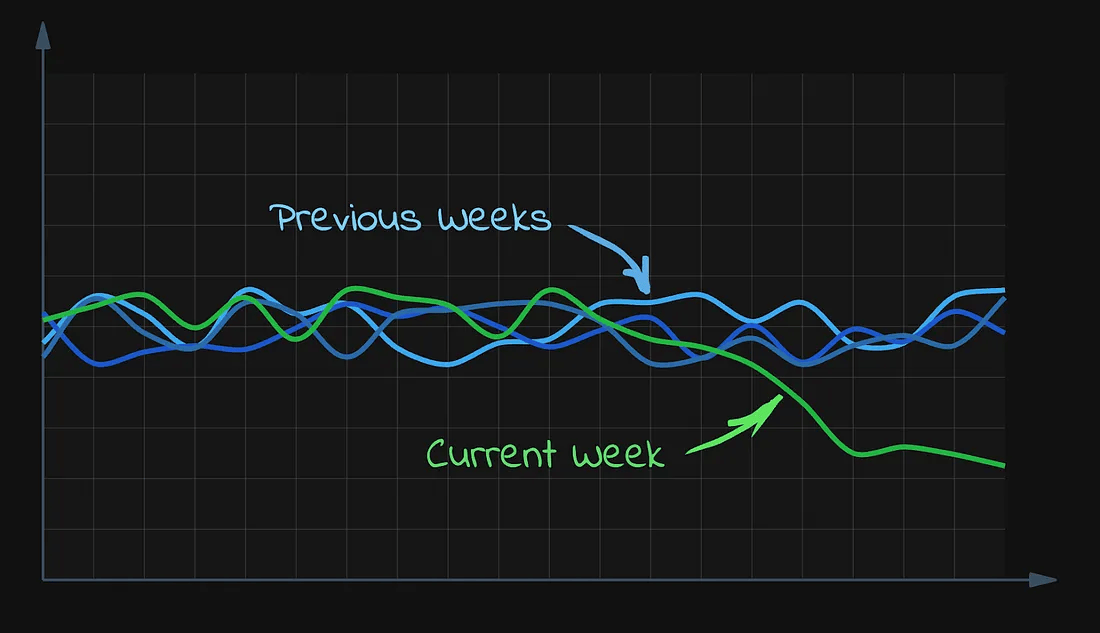
本周(绿色) vs 多周历史数据(蓝色)
现在就清晰多了,可以明显看出有什么地方不对劲。那么,如何把这种发现转化为告警机制呢?这正是 Z 分数派上用场的时候。
第一步是计算均值(mean)。
通常,我们会在一个特定的时间窗口内计算,但为了简单起见,这里我们对除当前周外的所有历史数据计算均值:
多周历史数据的均值
接下来,我们计算标准差(standard deviation):
多周历史数据的标准差
一旦我们拿到了历史数据的均值和标准差,就可以为当前周的每个数据点计算 Z 分数了:
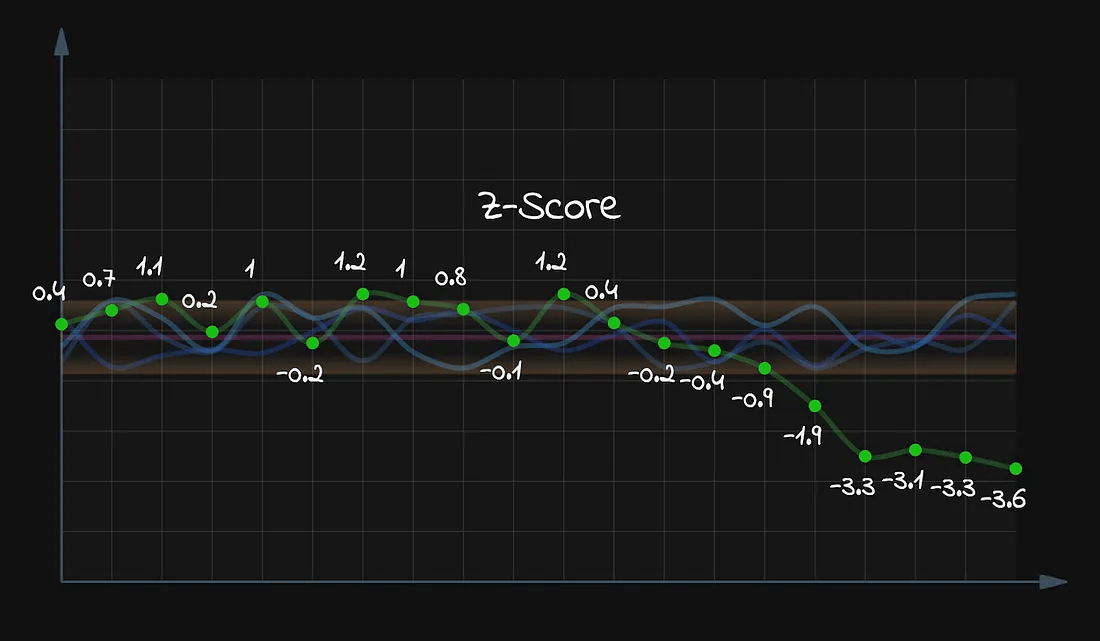
本周数据点的 Z 分数
注意到什么了吗?
所有“异常”的点,它们的 Z 分数都小于 -3。
而这其实是一个非常好的告警阈值!
为了更好地理解不同 Z 分数的意义,我们可以查阅 Z 分数表:
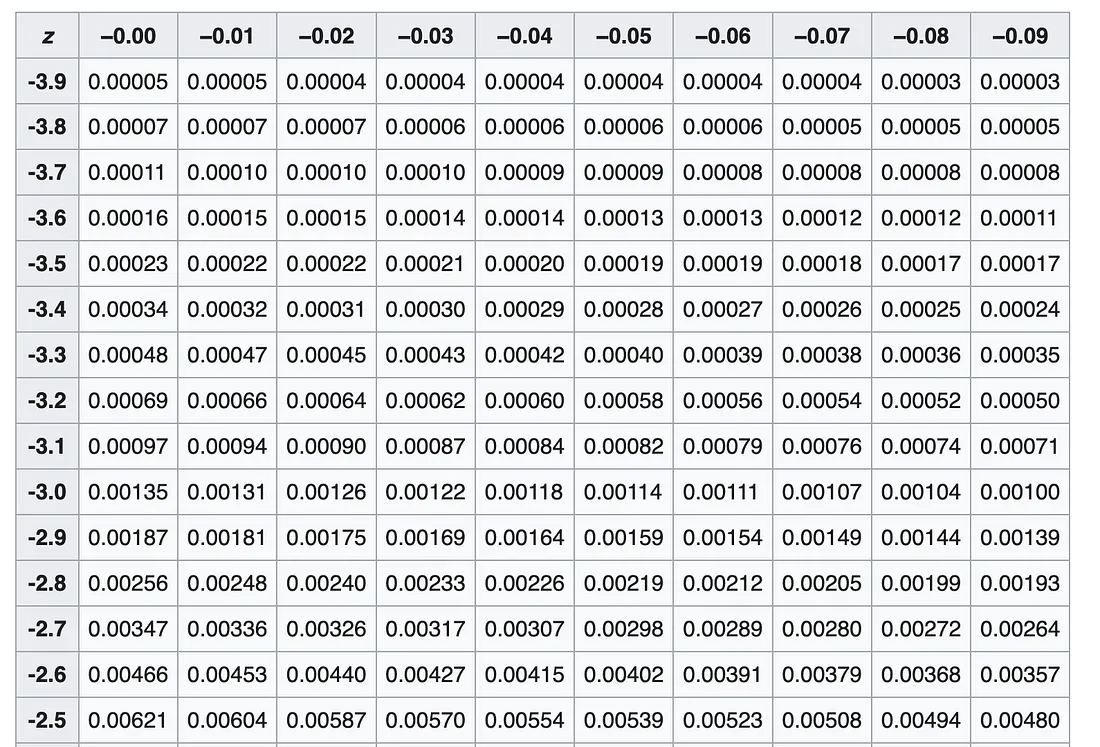
Z 分数表
通过这个表,我们可以知道每个 Z 分数代表的含义。
比如,Z = -3 时,只有 0.135% 的数据点低于这个值,说明这是一个非常罕见的事件。因此,将 Z = -3 作为异常检测的阈值是很合理的。
不过,很快我们也意识到,仅仅依赖 Z 分数来设置告警,也有它自己的局限性……
基于 Z 分数告警的问题
在使用 Z 分数告警时,我们遇到的最大挑战是:
我们的业务指标存储在 Graphite 中,而 Graphite 并不提供一种直接的方法来定义时间窗口用于计算。
最接近的现有功能是 movingAverage,但那并不太有帮助。
如果我们尝试基于过去四周的数据来计算标准差,最终得到的情况大概是这样:
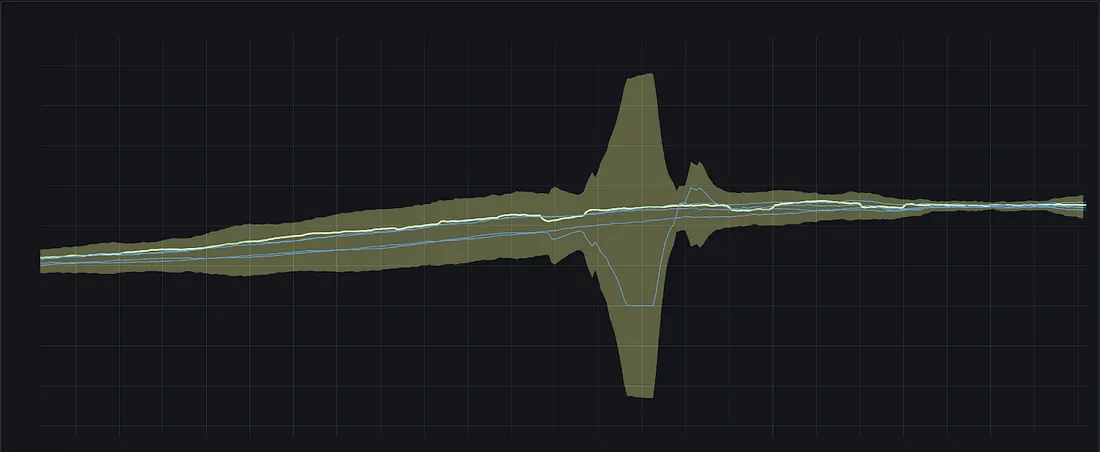
基于带异常历史数据的标准差计算结果
即使我们设法解决了滑动窗口的问题,并成功过滤掉了过去的异常事件,
仍然存在其他问题。
当我们开始用 Z 分数来触发告警时,很快就发现在夜间告警数量激增。
原因是什么呢?
因为某个国家或大洲的用户在夜间自然活跃度下降——人们在睡觉!
交易数量减少,波动性也随之下降,这使得 Z 分数在低活跃时间段变得更加不稳定,容易引发大量误报。
另一个基于 Z 分数告警的重大缺陷是:
它对人类来说不可直观理解。
当告警信息只是一些抽象的统计值时,很难快速判断事件的实际影响。
想象一下,在半夜被这样的告警吵醒:基于带异常历史数据的标准差计算结果
即使你打开仪表板查看数据,也很可能还是难以理解问题到底有多严重。
而如果告警信息改成这样就要实用得多了:
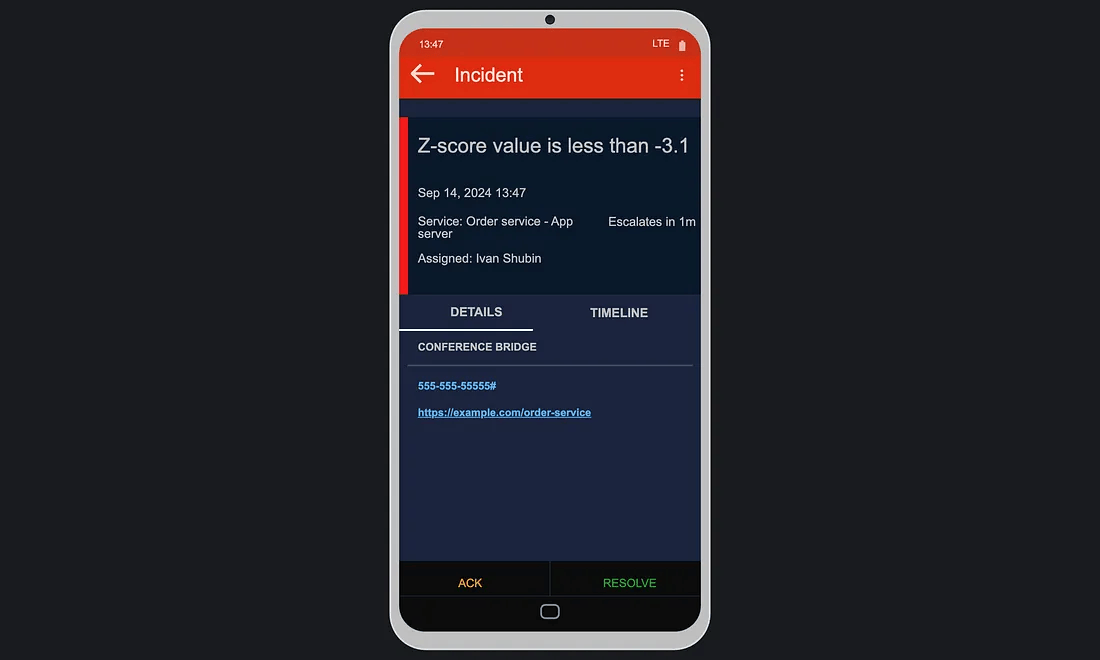
“过去10分钟内已处理订单的 Z 分数异常低(-3.1)。”
这样的信息可以直接行动,而且根本无需打开仪表板去查数。
综合考虑这些问题,我们意识到:
仅靠 Z 分数进行异常告警并不是适合我们的最佳方案,我们需要找到一种更好的方法。
替代方案(Alternative Approach)
鉴于基于 Z 分数告警存在可读性的问题,
我们开始思考:也许预测指标应该达到的水平,比单纯用统计方式标记异常更好。
但是,由于许多业务指标本身波动性很大,预测一个单一的数值并不理想。
因此,我们决定构建一个范围——即预测一个上限和下限,
以便在面对高波动指标时能够容忍一定的不确定性。
另一个挑战是:
仅靠 Graphite 的能力不足以支持我们所需的计算。
于是,我们决定开发一个小型服务,它的唯一职责就是计算预测范围,并将结果回写到 Graphite。这样一来,该服务本身不负责告警或异常检测,
而是由像 Grafana 这样的工具来完成检测和通知。
我们则可以专注于不断优化预测范围的算法,而Grafana负责实际的检测与通知。我们把这个服务命名为 "Granomaly",
下面是我们异常检测系统的整体概览:
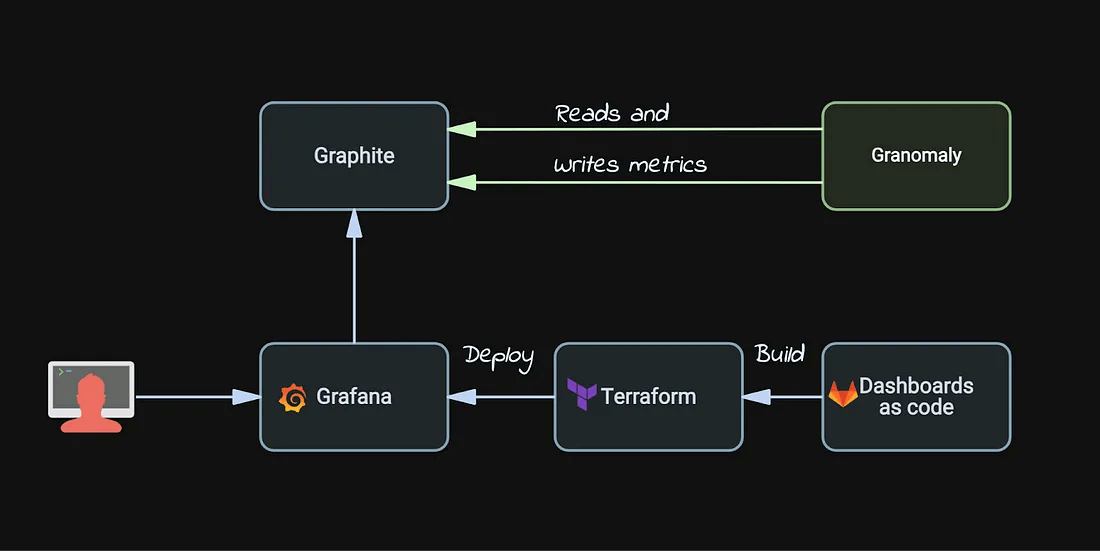
Granomaly 系统概览
Granomaly 是如何工作的?
Granomaly 服务的工作流程如下:
- 从 Graphite 读取历史数据(例如,特定指标过去4–5周的数据)。
- 过滤掉历史数据中的异常值。
- 计算预测范围(上界和下界)。
- 将预测范围作为两个独立的指标写回到 Graphite。
而实际的异常检测和告警,则是在 Grafana 中完成,基于 Granomaly 生成的预测范围来进行判断。
由于 Grafana 在可视化这些指标时也承担了大量计算工作,我们后来意识到有必要将仪表板管理为代码,
不过这是另一个主题,本文不展开讨论。
我们是如何计算预测范围的?
市面上有很多种异常检测算法,
但我们希望从简单的方法入手。
我们的第一个方法是:使用滑动窗口,基于历史数据,来确定每个时间点的上界和下界。
具体方法如下:
- 对于每一个新的数据点,取一个时间窗口(例如 20 分钟),
- 查找过去 4–5 周中同一星期几、相同时间段的历史数据。
- 然后,计算: 第 N 个百分位数作为下界, 第 (100-N) 个百分位数作为上界。
举个例子:
如果我们要评估 12:00 的一个指标,那么我们会收集过去几周中,每周11:50 到 12:10之间的历史数值。
如果我们选择 5 作为百分位数参数,那么就将第 5 个百分位数作为下界,第 95 个百分位数作为上界,从而构建预测范围。

Granomaly 算法示意(动画)
我们在多个指标上测试了这种方法,结果表现非常好!通过调整百分位数参数,我们甚至能够生成平滑的预测范围,既能够考虑到历史异常,又能避免这些异常扭曲未来的预测。
不过,很快我们发现:
当遇到大规模故障或多起重叠异常事件时,
这种方法开始显得力不从心了……
过去几周指标中的重叠故障问题
虽然不常见,但我们偶尔会遇到一个问题:
由于过去在同一星期几、同一时间段发生了多起重叠的异常事件,导致我们的预测范围被扭曲。
下面是一个例子:
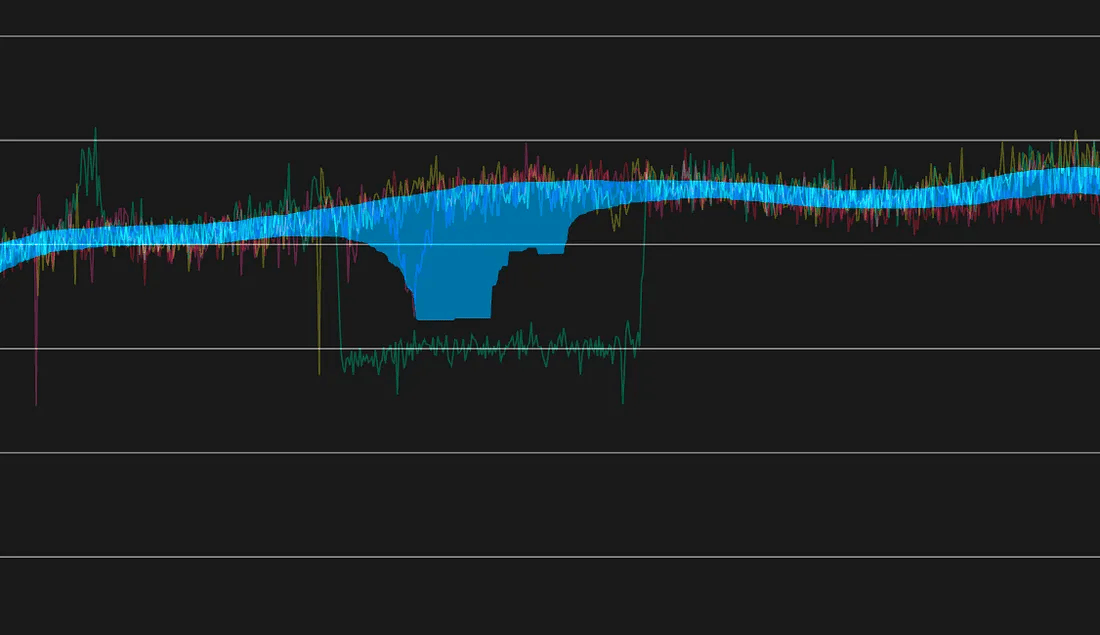
由于历史异常导致预测范围出现伪影(artifact)
可以看到,在有两周的时间里,指标在大致相同的时间点出现了下降。
在这种情况下,基于百分位数的方法很难生成一个可靠的预测范围。
这让我们意识到,必须有办法对历史数据中的异常进行修正。
但是,该怎么做呢?我们并不希望手动追踪每一次异常并排除,
因为我们的目标是让 Granomaly 保持尽可能简单。
于是我们决定采用另一种统计方法:能否自动排除偏差最大的那部分数据点?
第一次尝试:排除最偏离的一周
我们最初的想法是:
删除导致偏差最大的那一周,逻辑很简单:
- 取过去 N 周的数据;
- 生成 N-1 组组合,每次排除一周;
- 分别计算每组组合的数据标准差;
- 选择标准差最小的那组组合作为最终数据集。
这种方法在存在严重异常的情况下确实能够有效过滤出大幅异常,
但很快我们发现了一个严重缺陷:
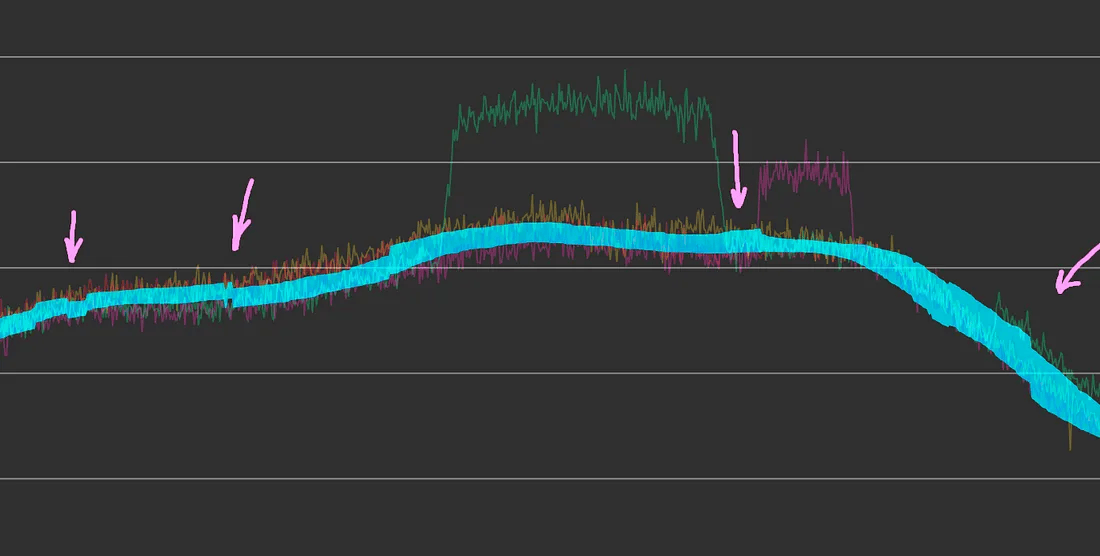
在排除了异常周后,预测范围仍然出现多个伪影(artifact)
那么,到底发生了什么?
问题在于:这种方法总是假设存在异常周需要排除,即使实际上没有异常也强行剔除一周。这导致预测范围变得非常不稳定,在正常使用场景下变得不可靠。
显然,这不是一个正确的解决方案。于是我们重新审视了思路,并最终提出了一个更优秀的方法。
异常值排除(Outlier Exclusion)
在这一步,我们决定使用一点统计技巧——我会通过两个例子来解释。
在任何一个给定的时间点,我们分析的是过去几周中同一天、同一时间的数据点。
假设我们看到以下这组数据:
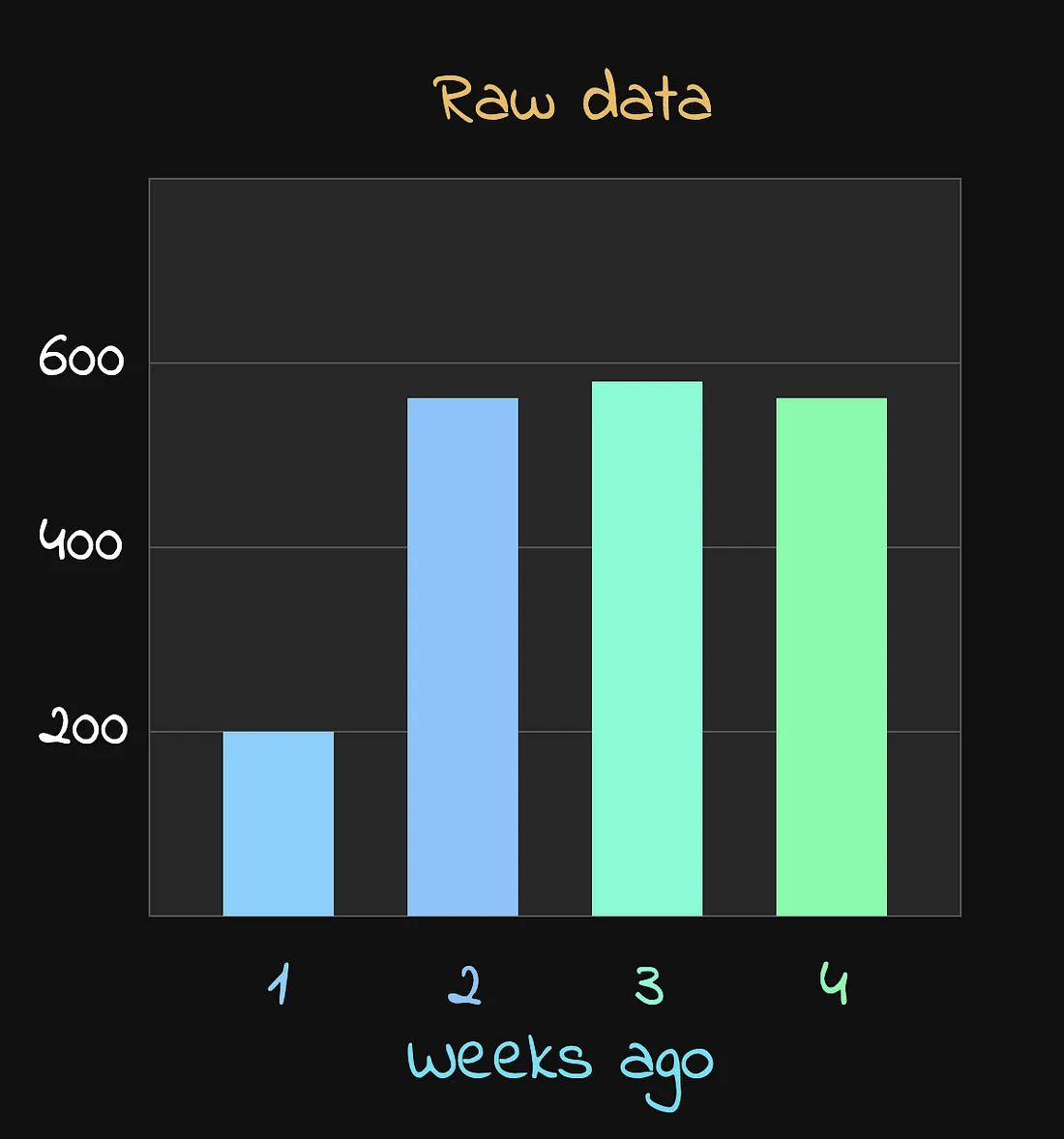
在多个星期中,同一时间点的指标数值
乍一看,很容易发现有一个异常值。大部分时间,指标都稳定在600左右,但一周前突然下降到 200。这明显像是一次故障或异常事件,因此在计算预测范围时,不应该包含这周的数据。
第一步:计算 Z 分数(Z-Scores)
为了解决这个问题,我们首先对这些值计算标准差,然后求出每个数据点的绝对 Z 分数:
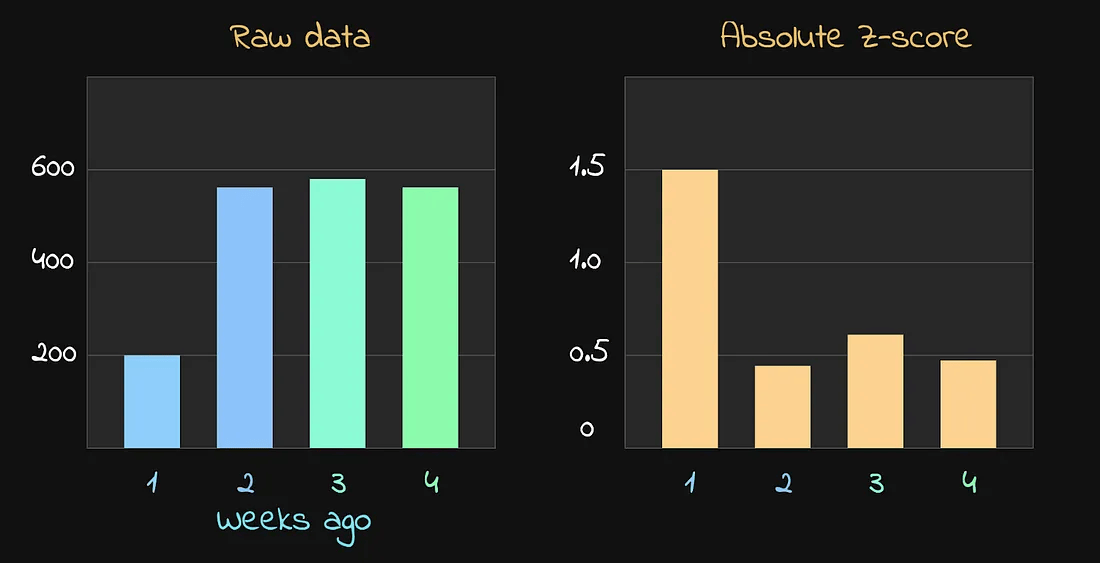
每周对应的 Z 分数
正如预期的那样,第1周的 Z 分数最高,显然是一个异常值。但我们并没有简单地通过设定一个固定的 Z 分数阈值来过滤,而是采取了进一步的步骤:
第二步:Z 分数归一化(Z-Score Normalization)
这里就有趣了。
我们不是直接基于一个固定的 Z 分数阈值来筛选,
而是做了Z 分数的归一化处理:
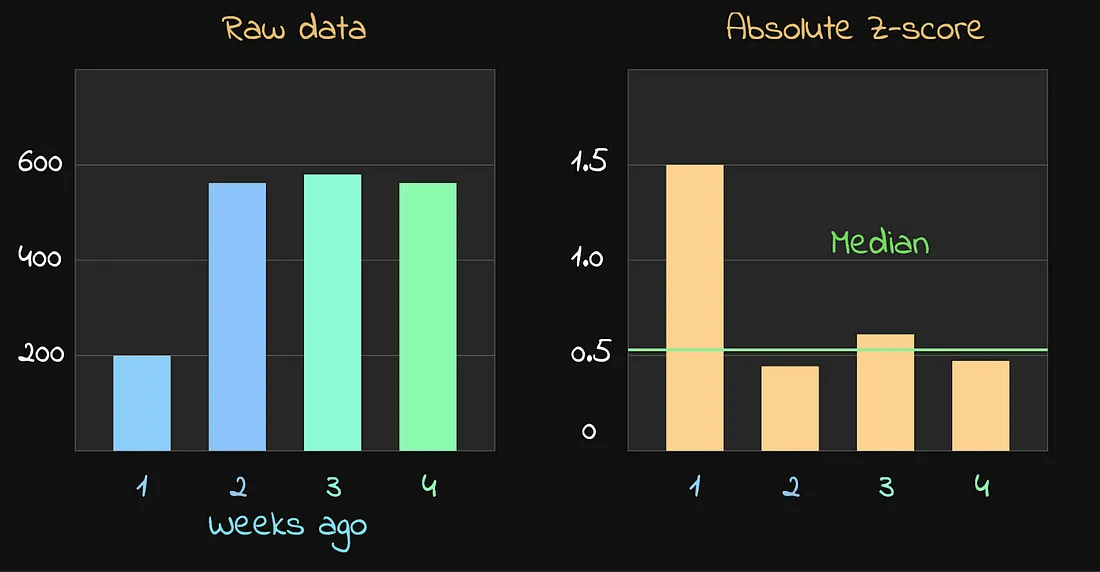
具体方法是:
- 先计算所有 Z 分数的中位数(median);
- 然后用中位数减去每个 Z 分数;
- 最后保留归一化后绝对值小于 0.6 的数据点。
这里的 0.6 阈值是通过经验确定的,但当然也可以根据需要进行调整。
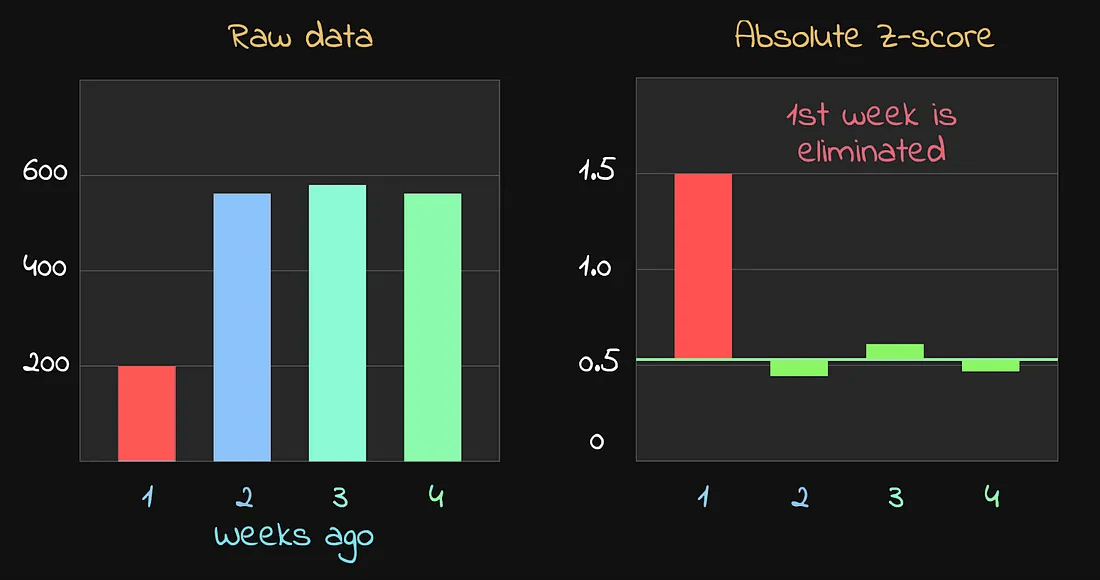
最终步骤 — 检测出异常值并从数据集中剔除
那么,为什么要做这种所谓的“归一化”处理?
为什么不直接对原始 Z 分数应用一个固定阈值呢?
在上面的这个例子里,直接使用固定阈值可能确实也能很好地工作。但是,为了真正理解归一化的价值,我们需要看看算法在没有明显异常的情况下会表现得怎样。
一个没有明显异常的案例(A Case with No Obvious Outliers)
来看这样一组数据,
其中没有任何异常事件发生:
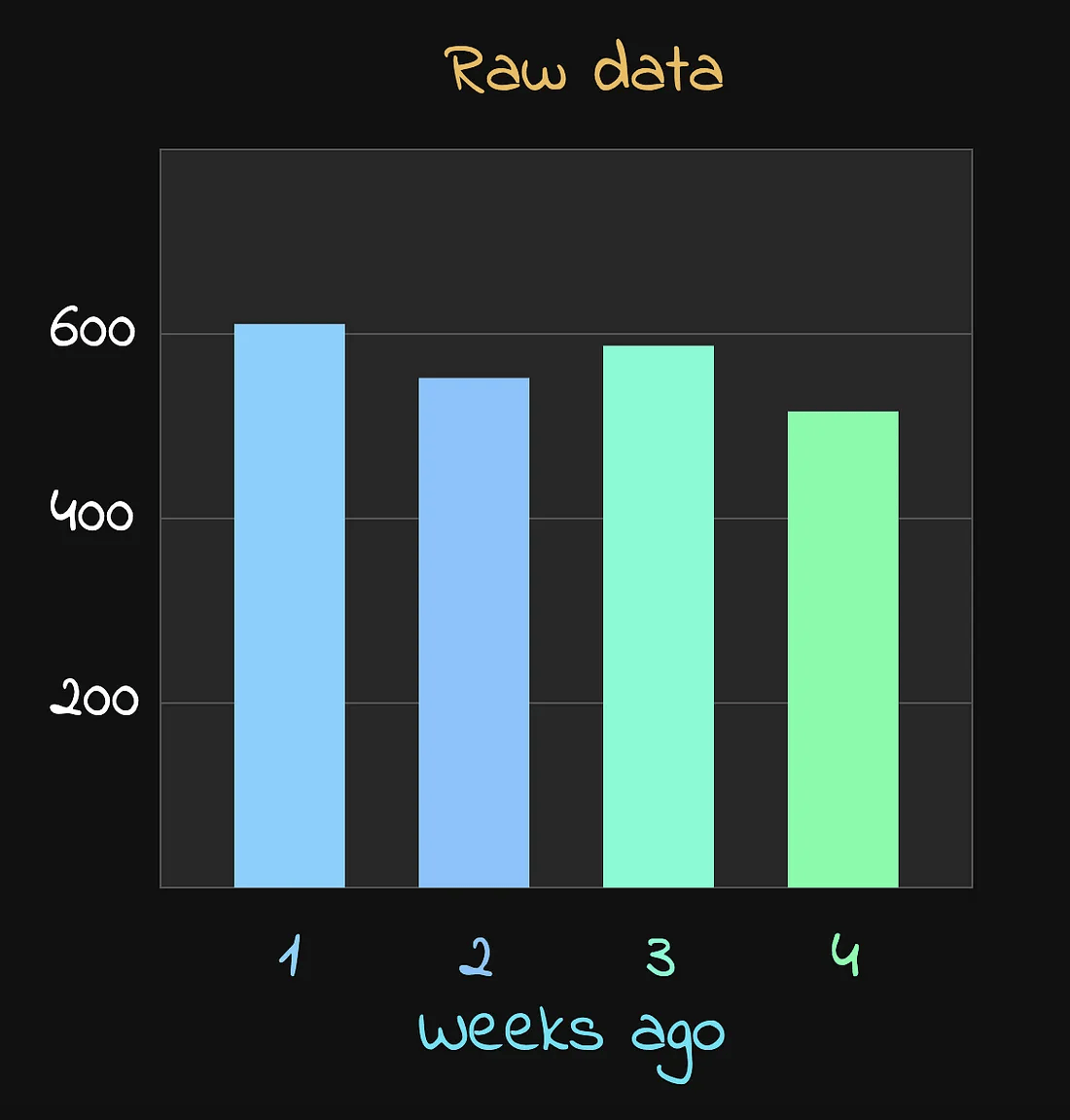
在多个星期中,同一时间点的数据,没有明显异常
乍一看,一切都很正常——这看起来就是一个典型的正常数据集。
理想情况下,在这种情形下,我们的方法不应该排除任何数据点。
现在,我们按照之前的步骤进行处理。
首先,计算每个数据点的绝对 Z 分数:
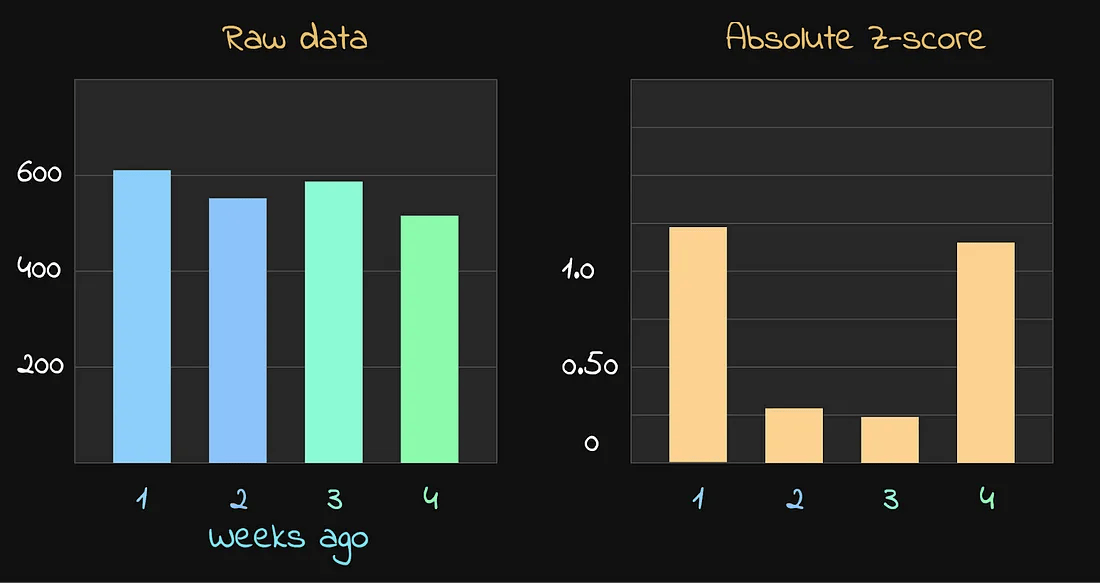
每周对应的 Z 分数
可以看到,第1周和第4周的数值稍高或稍低,
因此它们的 Z 分数相对较高。然而,从人的角度来看,这种波动实际上并不构成真正的异常。
这正是我们要用中位数归一化 Z 分数的原因。
归一化后的结果如下:
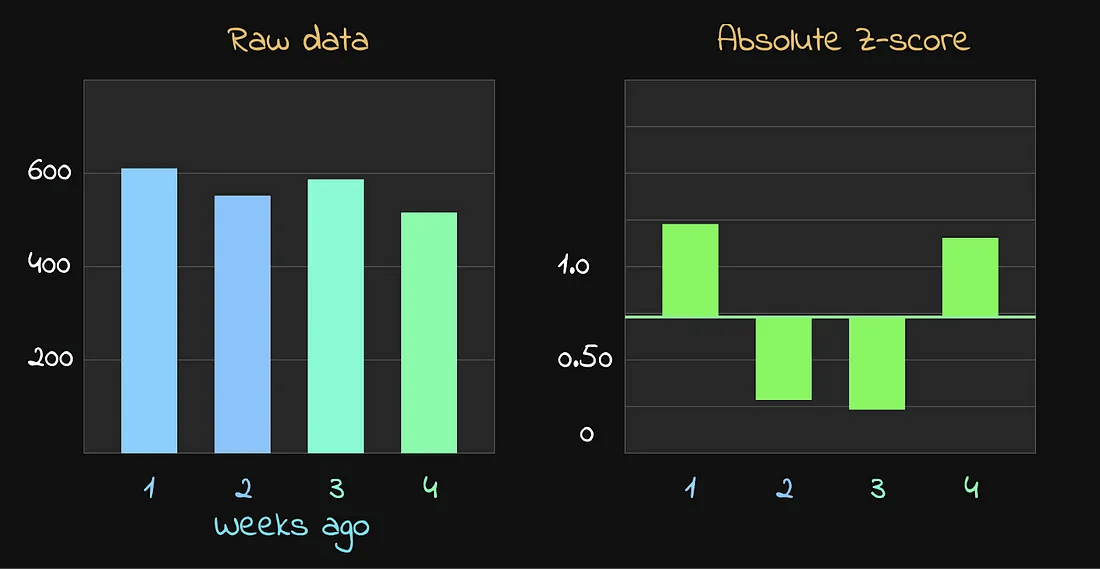
归一化后的每周 Z 分数
在这里,所有数据点的归一化 Z 分数都没有超过 0.6 阈值,
因此没有任何数据点被过滤掉——
这正是我们希望看到的正确行为。
真实世界数据(Real-World Data)
那么,这种方法在真实场景中表现如何呢?
这是我们之前讨论过的例子,在应用了异常剔除后的预测范围效果:
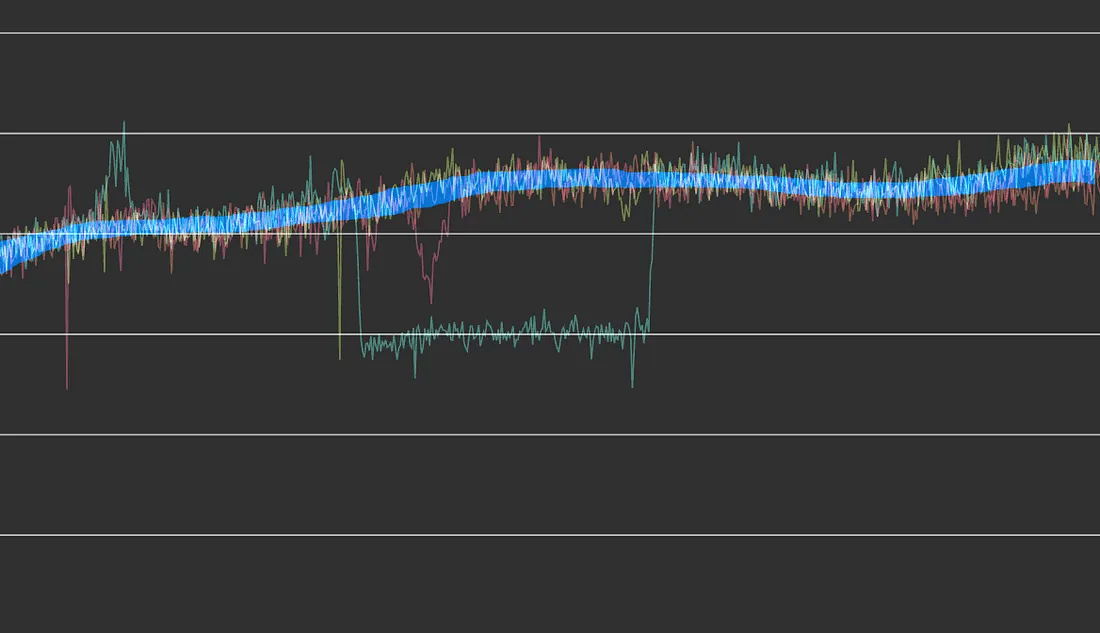
在历史数据中剔除异常后,平滑的预测范围
再来看另一个更复杂的案例,其中有两周出现了重叠的异常事件:
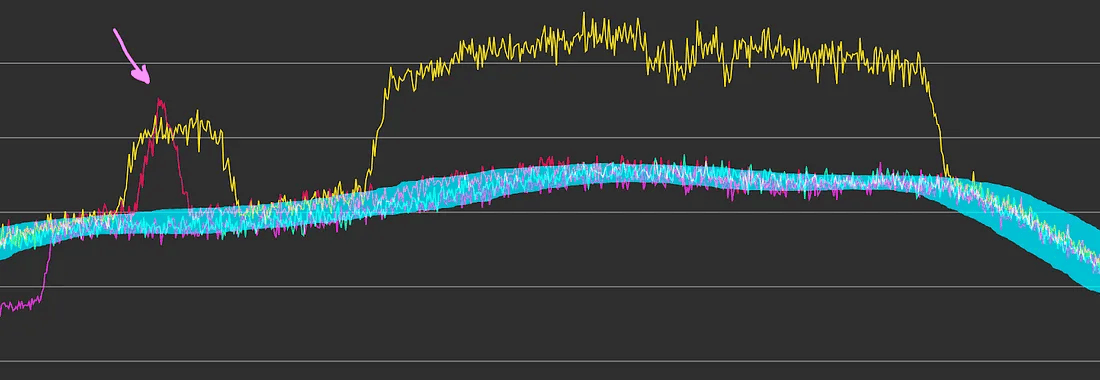
在剔除多个异常后,预测范围依然平滑
如你所见,即使两周发生了不同的异常事件,预测范围依然保持了平滑和稳定。
现在,既然我们已经有效地剔除了历史异常,就可以开始进行实时的真正异常检测了。
检测异常(Detecting the Anomalies)
正如前面提到的,Granomaly 服务本身并不直接检测异常,
它只是生成预测范围的指标。
但一旦有了这个指标,我们就可以用任何能访问到它的工具来轻松进行异常检测。
我们最终决定直接在 Grafana 中实现异常检测。
这种做法带来了快速的反馈循环,可以快速试验不同的检测策略。
下面是我们团队使用的异常检测仪表板示例:
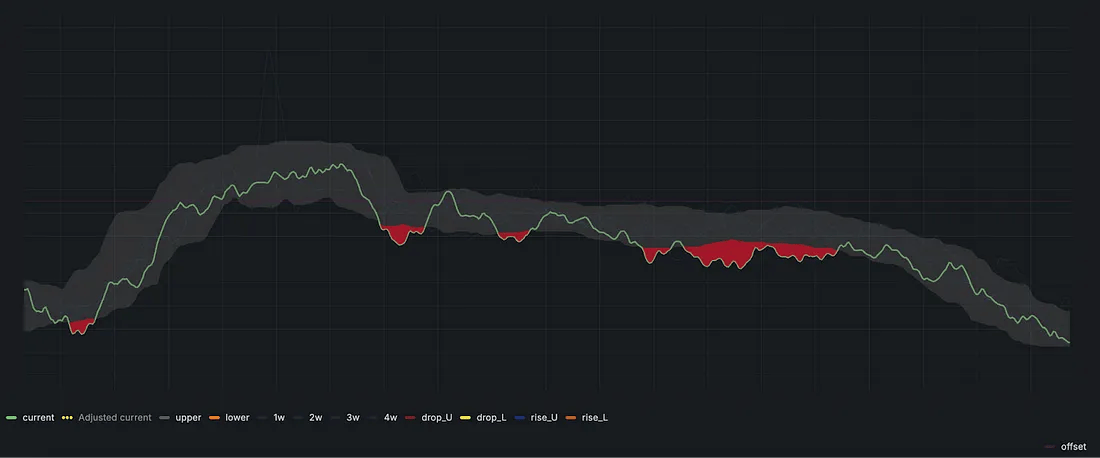
Grafana中的异常检测仪表板
我们配置了仪表板和告警:
只要某个值超出了预测范围,就被视为异常。
对于每一个指标,我们设置了两种告警:
- 一种用于检测显著下降;
- 另一种用于检测长时间内的缓慢下滑。
这样,我们既能捕捉到突发性故障,也能发现缓慢恶化的“慢烧型”故障。
当然,每个指标的阈值设置是不同的。为了简化 Grafana 配置、降低 Graphite 查询的复杂度,
我们在 Granomaly 服务中引入了一个新的概念:
“偏移量(offset)指标”。
“偏移量(Offset)指标”
偏移量表示当前指标值与预测范围的差异:
- 如果当前值在预测范围内,偏移量为 0。
- 如果当前值高于预测上界,偏移量 = 当前值 - 上界。
- 如果当前值低于预测下界,偏移量 = 当前值 - 下界。
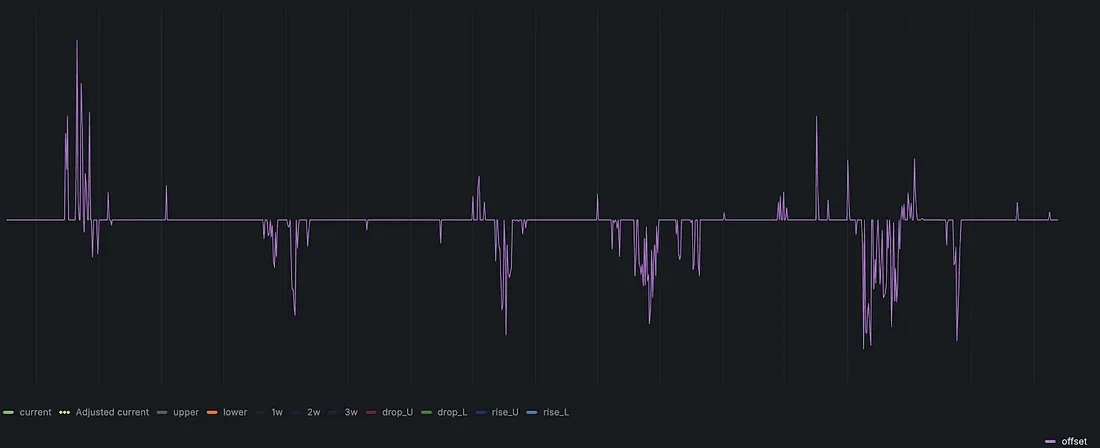
偏移量(Offset)示意图
这样,告警配置就变得非常简单:
- 只需在一定时间段内累加所有最新的偏移量值;
- 将这个总和与一个阈值比较, 决定是否触发告警。
针对特殊事件的修正(Correcting for Events)
虽然我们依赖异常检测系统已有一段时间,但很快又遇到了一个新挑战:
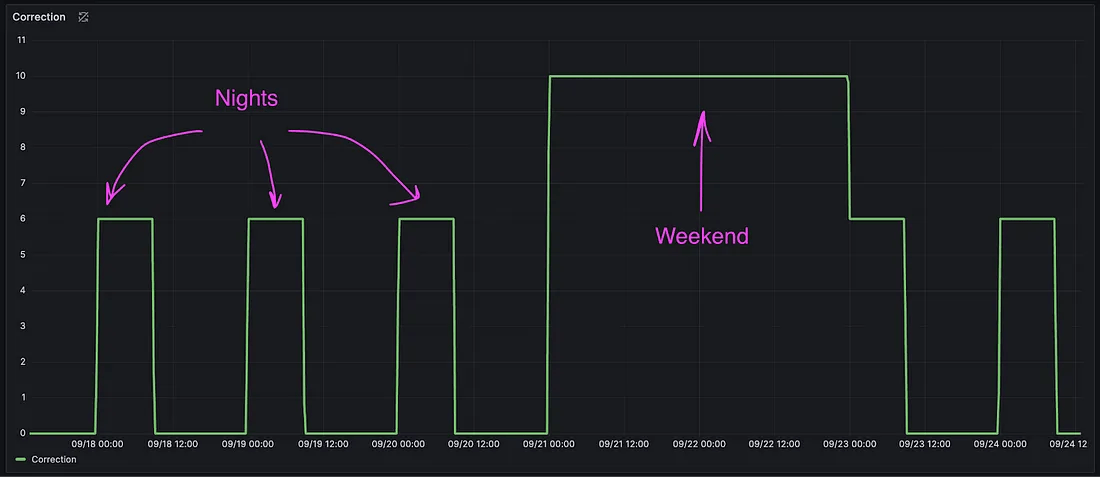
在像假期、周末、超级碗(Super Bowl)、世界杯(World Cup)等特殊时期,如何微调告警?
我们知道,在这些时期,业务指标的行为模式与平时不同,
如果不调整预测,就容易出现大量误报或漏报。要在 Grafana 的告警系统中配置这些复杂情况,十分麻烦,
于是我们采用了另一种方法。
我们希望能够:
- 为特定时间段指定一个调整值;
- 要么调整告警阈值,
- 要么直接调整预测范围指标本身。
于是,我们提出了**“修正(Correction)指标”**的概念。
修正指标(Correction Metric)是如何工作的?
修正指标非常灵活,在 Granomaly 服务中配置:
- 默认情况下,修正值为 0,表示不进行任何修正。
- 对于特殊事件(如节假日),我们可以定义一个任意的修正值(例如 10)。
- 这个值会被作为百分比调整,用来扩展预测范围。
- 最终,偏移量指标是基于修正后的预测范围计算的。
这种方法让我们能够提前为已知事件做好准备,既保证了异常检测的准确性,也提升了系统的可控性与可靠性。
在业务指标表现超常时检测异常(Detecting Anomalous Drop While Outperforming)
我们还遇到了另一个有趣的问题:
当业务指标超出预期(超常发挥)时,如何检测其中的小型异常?
举个例子:某一时期内,我们的流量比预期高出了 15–20%,但与此同时,发生了一个小型事件,导致指标略微下滑。
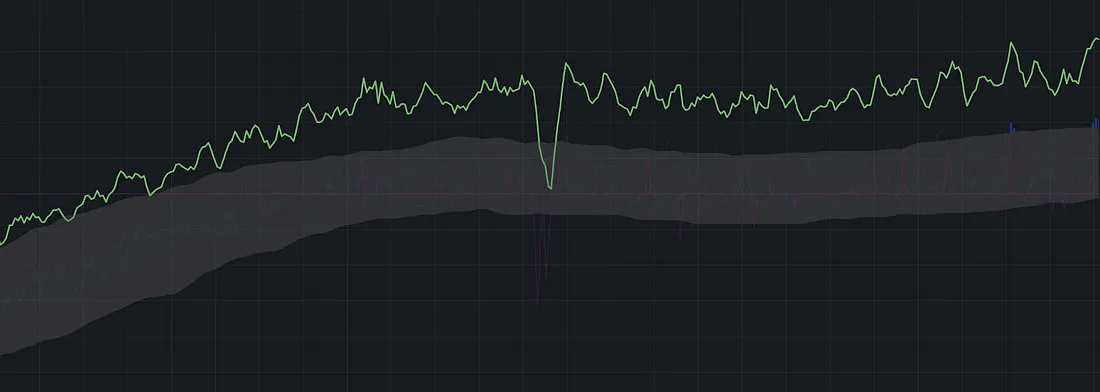
在超常指标中的小幅下降示例
如上图所示,因为整体流量大幅上升,这次小的下滑几乎没有触碰到预测范围的下界,因此这种小异常很容易被忽略。
从技术上讲,这里其实存在两种异常:
- 整体流量的异常上涨;
- 涨幅期间的小幅下降(被上涨掩盖了)。
虽然我们可以使用修正指标(Correction Metric)来应对,但由于这种情况是突发且不可预期的,我们希望采用一种更灵活的策略。
引入“调整因子(Adjustment Factor)指标”
为了更好地处理这种场景,我们在异常检测仪表板中新增了一个组件:
调整因子(Adjustment Factor)。
概念很简单:
- 回看过去几个小时内的指标数据;
- 计算出一个单一的调整因子, 使得当前指标乘以这个调整因子后,能更好地落在预测范围内。
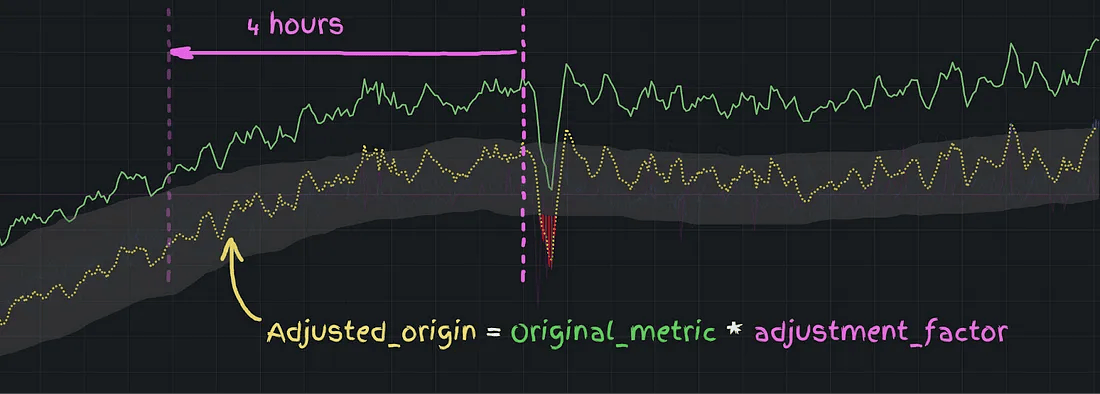
调整后的指标示意图
一旦得到了这个调整因子,我们就绘制出调整后的原始指标(adjusted origin)。
然后配置告警系统,只要原始指标或调整后的指标出现下降,就触发告警。
这种方法让我们即使在指标整体超常波动时,也能准确检测到潜在的异常下滑,
确保不会因为业务的超常表现而漏掉真正的异常事件。
模拟异常与故障(Simulating Anomalies and Outages)
如你所见,在上述异常检测流程中涉及了大量组件,设置正确的参数或微调异常排除算法本身就是一项很大的挑战。
每当真的发生一次事故时,我们都会感到高兴,因为这意味着可以用真实数据测试我们的系统表现如何。
但可惜的是,我们并不总有“幸运”遇到实际故障来测试。
为了解决这个问题,我们想出了一个模拟(simulation)方法。
核心思路是:
在将异常检测仪表板部署到 Grafana,并在 Granomaly 服务中配置之前,
你可以先在模拟环境下测试它在特定指标上的表现。
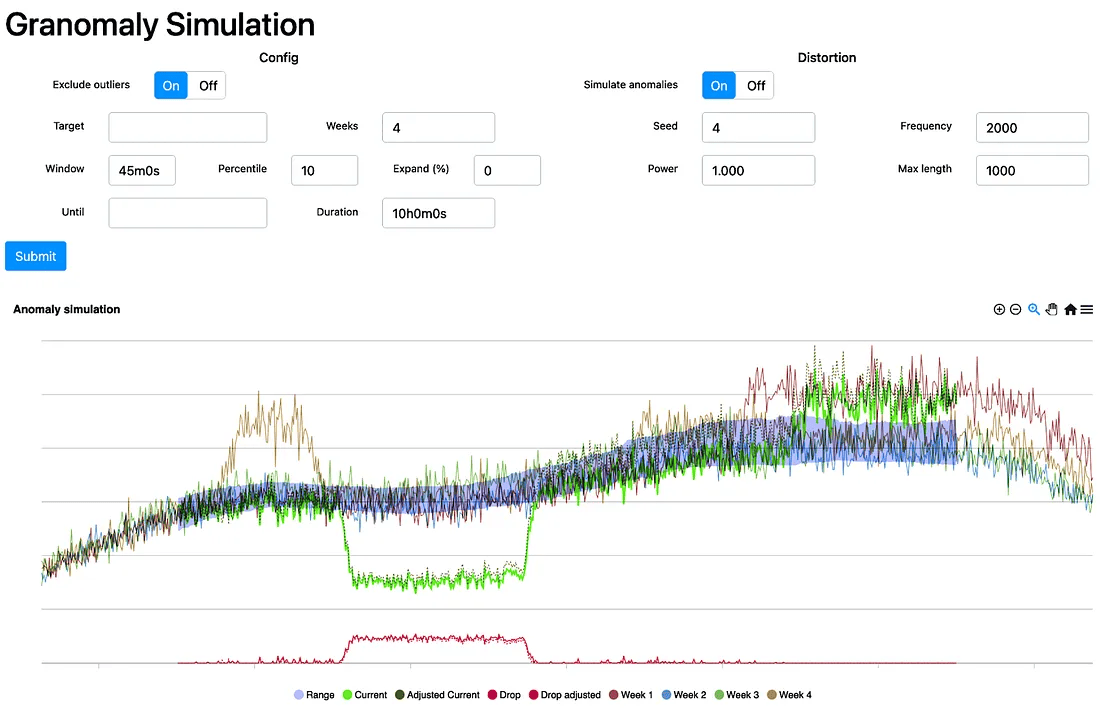
Granomaly模拟界面
于是,我们在 Granomaly 服务中开发了一个模拟页面,允许用户配置所有参数,并测试所选指标会产生怎样的预测范围。
除此之外,我们还添加了对各种指标异常情况的模拟功能,可以测试异常值排除算法的表现。
这极大地提升了系统的可用性:
- 我们可以不断打磨预测范围计算算法;
- 在各种复杂场景(如两周内出现重叠异常)下进行测试;
- 任何人都可以直接输入一个指标,立即查看结果。
这种极大缩短的反馈周期,让我们可以更轻松地为每个指标微调预测范围,
从而确保更精准的异常检测。
理解异常(Understanding the Anomaly)
那么,我们搭建了这一整套系统之后,有用吗?
我们真的能有效检测到异常吗?
答案是——
检测到异常本身其实并不难。
真正的挑战在后续处理。
你看,如果系统中出现了大量错误,通常可以追溯到某个故障组件。
但如果根本没有任何系统错误呢?
只是比如说,网站上的订单数量突然下降,系统里又没有任何异常日志或改动迹象?
那你发现了这个异常后,接下来怎么办?
可能的原因有很多,比如:
- 只是因为天气太好了,人们外出,不上网;
- 有什么大型活动你忘记了,用户都去看直播了;
- 市场营销活动出了问题,广告投放突然停了;
- 合作伙伴出了问题,但他们自己还没发现,已经开始影响到你了;
- 又或者是某个新的A/B测试导致订单按钮的点击事件出错, 让一部分用户根本无法提交订单。
任何事情都有可能发生。
所以你看,发现异常并不难,难的是——在发现之后,应该做什么?
一个非常有效的策略是:
把核心业务指标拆分成多个子指标。
比如:
- 不只是追踪整体订单数量, 要按区域划分订单;
- 按设备类型划分,比如 iPhone、Android、平板、桌面浏览器等;
- 按营销渠道划分,这一点尤其重要, 因为公司通常依赖各种渠道吸引用户, 而这些渠道中很多是依赖第三方服务的, 必须确保外部系统的异常不会悄悄影响到自己。
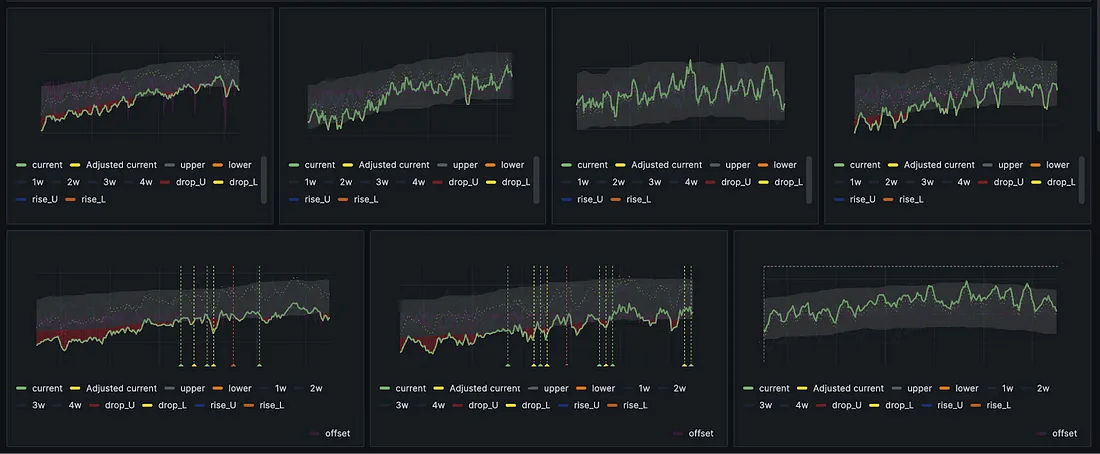
将单一指标拆分为多个子指标
一旦你能把核心业务指标拆分成细粒度的组成部分,就可以扩展异常检测仪表板,覆盖所有这些子指标。
这种做法能够帮助你:
- 在数据出现异常行为时迅速缩小排查范围,
- 提高问题定位速度,
- 提升整体监控系统的智能性与敏捷性。
结论(Conclusion)
即使仅仅使用像Z 分数、标准差、百分位数等基本的统计工具,异常检测也可以非常有效。
你不需要成为机器学习专家,也能为时间序列数据构建一个实用的异常检测系统。
但确实存在一些关键挑战需要克服,比如:
- 如何处理历史数据中的异常,
- 如何通过模拟缩短反馈周期,
- 以及如何理解检测到的异常现象。
正如本文展示的那样,统计方法可以成功识别出异常值,但其有效性高度依赖于历史数据的质量。
如果历史数据中存在异常而没有被清除,那么预测结果就会受到扭曲,因此,过滤掉历史异常变得尤为重要,这也是我们通过自己的一套方法专门解决的问题。
交互式模拟(Interactive simulation)
在整个过程中起到了至关重要的作用:
- 将反馈周期从数天缩短到了几秒钟;
- 使我们能够快速在历史数据上进行实验;
- 更方便地调整参数;
- 也能评估某个指标是否适合用于异常检测。
并不是所有指标都适合这套方法,因此,优化反馈循环(feedback loop)是搭建异常检测系统时至关重要的一步。
然而,最具挑战性的问题是:
如何解释检测到的异常(interpreting anomalies)。
当某个指标出现突发性、大幅下降时,
通常很容易定位原因,因为这类异常往往伴随着其他报警信号,
能很快指向某个明确的系统故障。
但如果你遇到的是:
- 订单数量持续下降了10%,
- 没有错误日志,
- 没有客户投诉,
- 没有明显的技术问题,
那么,解释这样的异常就非常棘手了。
这种现象可能是由于:
- 细微的业务变化,
- 市场营销活动的问题,
- 甚至只是天气模式变化导致的用户行为变化。
这种不确定性,让异常解释变得非常困难。
将指标按区域、设备或营销渠道拆分,可以在一定程度上帮助缩小异常原因的范围,但显然并不是一个万能的解决方案。
最终,在你能够分析异常之前,首先你需要能够检测到异常。
而我希望通过这篇文章,想告诉你的是:
即使使用相对简单的统计方法,也完全可以做到这一点。
感谢阅读!